
ペパボ研究所 研究員の野村(@komei)です。 ペパボでは、自社が運用するウェブサービスのユーザの行動ログや属性情報などを収集・分析・活用するための基盤として「Bigfoot」を運用しており、今年Google Cloud Platform(GCP)を使った構成への移設を行いました。 本記事では、Bigfootの移設先であるGCPを用いて形態素解析を行う方法についてお話しします。
形態素解析を行う動機
ペパボでは、ユーザの行動ログや属性情報だけでなく、ユーザからのお問い合わせや商品情報など様々なデータをBigfootに蓄積しています。 これらのデータの中には、ユーザからのお問い合わせの文書や商品の説明文などの日本語の文書データも多く含まれています。 このような文書データから意味のある情報を抽出し活用するためには、まず文書に含まれている単語を把握する必要があります。 そして、TF-IDFやword2vecなどの手法を用いて文書の特徴を求めることで、推薦やサービスの改善など様々な方面での利用が行えるようになります。 具体的には、筆者が情報処理学会 第49回インターネットと運用技術研究会(IOT49)で発表した「ハンドメイド作品を対象としたECサイトにおける単語の出現頻度を用いた稀覯品検出」がその一例として挙げられます。 また、今後はユーザからのお問い合わせの傾向を解析し、サービスの改善に役立てていくことも一つの応用例として考えることができます。 ここまでに挙げたサービスの各種改善を行う上で、GCP上で形態素解析を行える環境を構築することは有用であると筆者は考えました。
kuromoji-for-bigquery
GCP上で形態素解析を行うために、kuromoji-for-bigqueryというオープンソースソフトウェアを利用しました。 kuromoji-for-bigqueryは、BigQueryの指定したテーブルにある文書データを入力として、kuromoji(日本語の形態素解析エンジン)による形態素解析の結果を、BigQueryの指定したテーブルに出力します。
kuromoji-for-bigqueryは、JavaとApache Beamで実装されています。 Apache Beamは、バッチもしくはストリーミングのデータ処理のパイプラインを定義するためのフレームワークです。 Apache Beamによって実装されたデータ処理のパイプラインは、ローカルもしくはGCPのCloud DataflowのようなApache Beamがサポートしている分散処理バックエンドで実行可能です。 kuromoji-for-bigqueryには、以下のようなデータ処理のパイプラインが実装されています。
- BigQueryからのデータの取得
- kuromojiを用いた形態素解析の処理
- 形態素解析の結果をBigQueryのテーブルに出力
このデータ処理のパイプラインの実行環境は、--runnerという引数で指定することができます。
本記事ではGCP上で形態素解析の処理を実行するため、--runner=DataflowRunnerを指定しました。このときのkuromoji-for-bigqueryの動作の流れを示します。
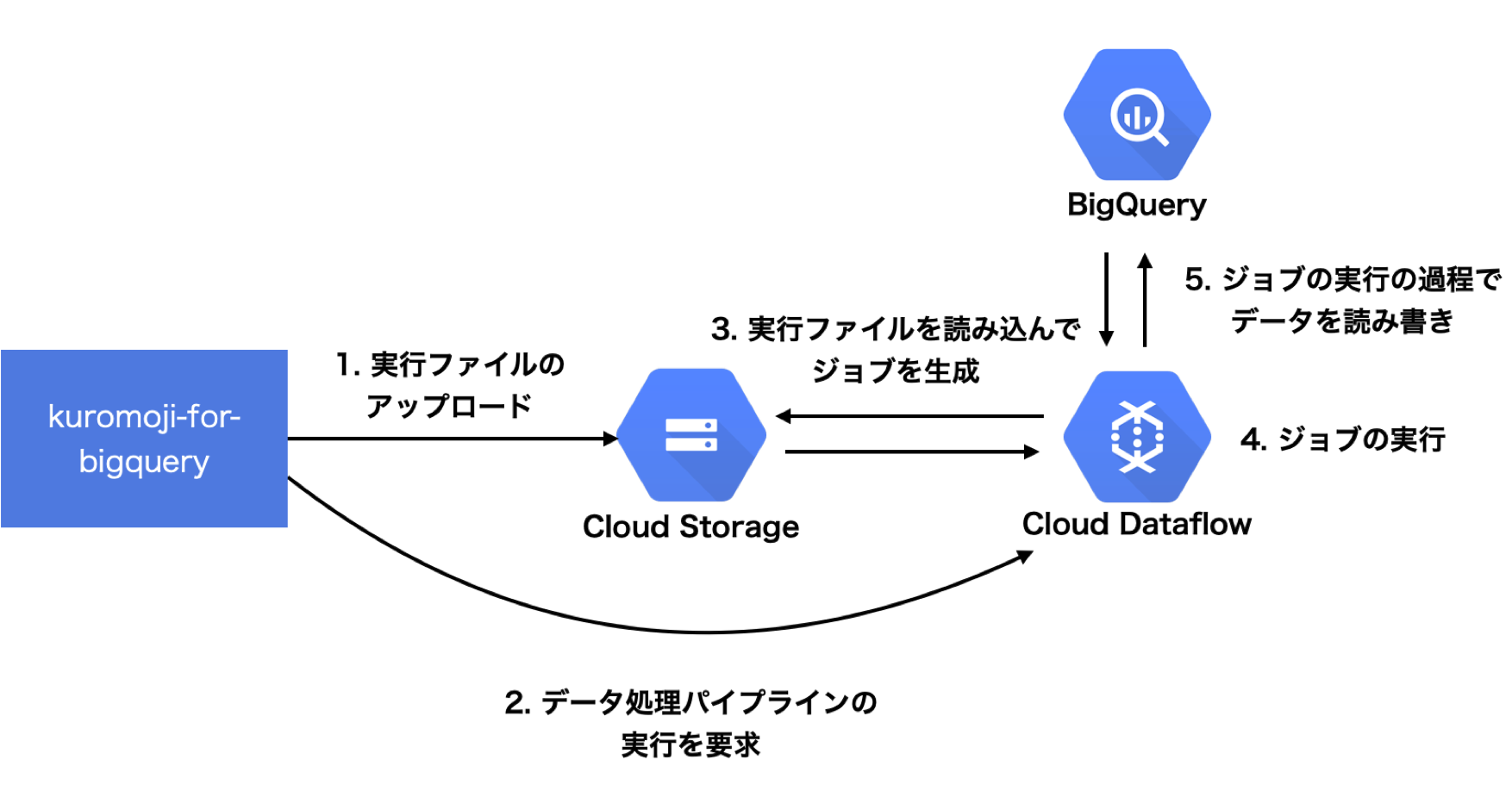
--runner=DataflowRunnerを指定し実行を開始すると、まず、データ処理のパイプラインが記述された実行ファイルをCloud Storageにアップロードし、その後、Cloud Dataflowにジョブの実行要求が送られます。
ジョブの実行要求を受けたCloud Dataflowは、Cloud Storageに保管された実行ファイルを参照し、ジョブを生成し実行を開始します。
そして、Cloud Dataflowは、kuromoji-for-bigqueryのデータ処理のパイプラインに従ってジョブを実行するので、BigQueryからデータを取得し、形態素解析の結果をBigQueryに出力します。
また、実際に生成されたジョブは、Cloud Dataflowのコンソール画面から確認することができます。これについては後述します。
形態素解析の結果
形態素解析の結果は指定したBigQueryのテーブルに保存されます。実際にkuromoji-for-bigqueryを使って形態素解析を行った結果を以下に示します。
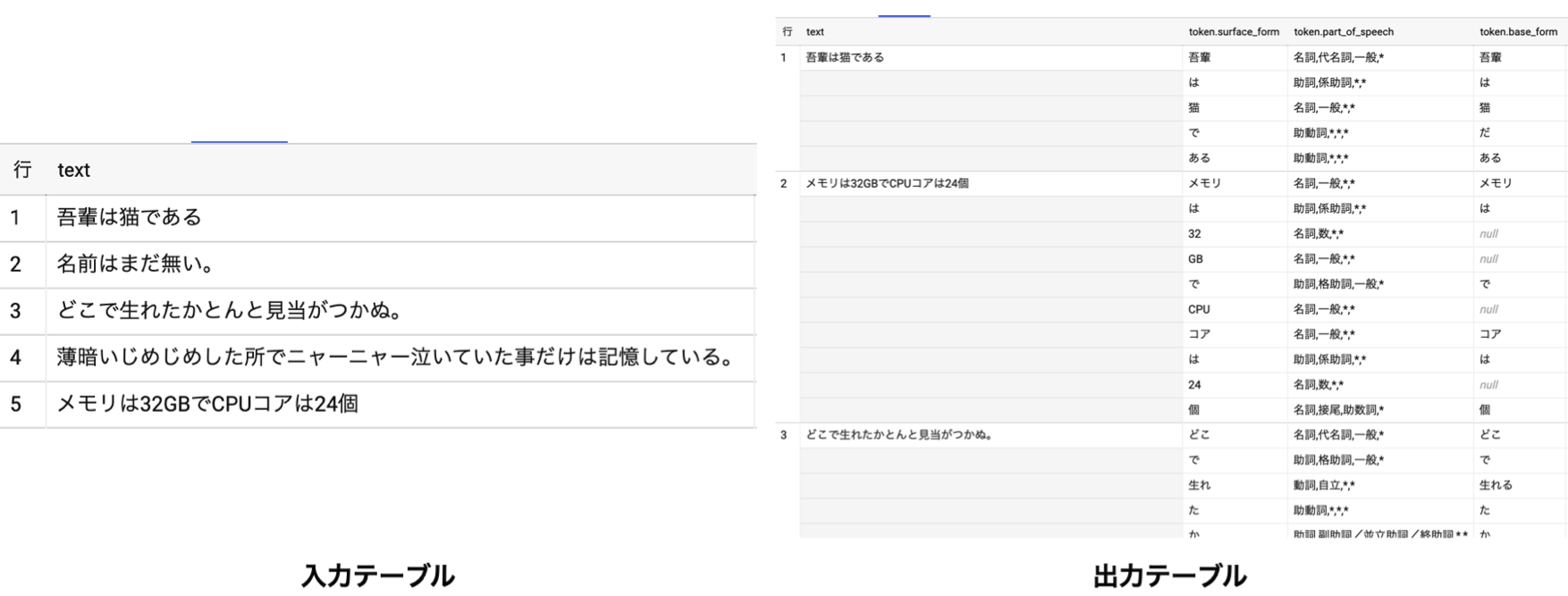
このように入力として与えたテーブルに保存された各文書を形態素解析した結果がテーブルに出力されます。 形態素解析の結果はBigQuery上のテーブルに出力されているため、クエリを書くことでTF-IDFの計算もBigQuery上で行うことができます。
Cloud Dataflowで生成されたジョブ
実際に生成されたジョブは、Cloud Dataflowのコンソール画面から確認することができます。以下に実際に生成されたジョブを示します。
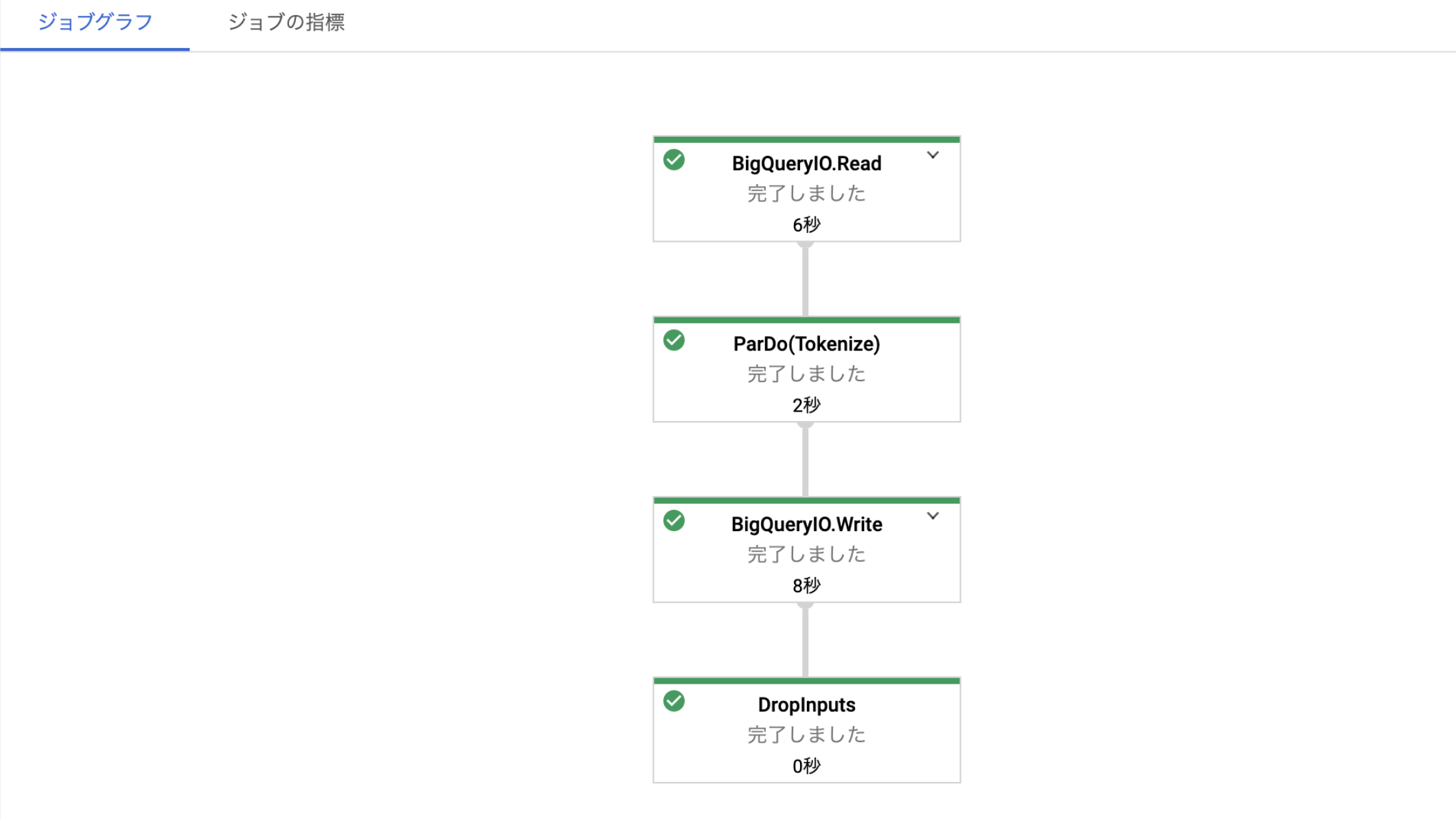
このジョブは、100件の文書を形態素解析したときのものです。 このジョブの実行グラフからBigQueryの読み書きや形態素解析の処理に要した時間を確認できます。 また、形態素解析などの処理とは別に、ジョブを実行するために必要なインスタンスの立ち上げなどに要する時間があるため、ジョブの全体の実行時間は5分28秒となっていました。
データ数による実行時間の変化
データ数による形態素解析とジョブの実行時間の変化について調査を行いました。以下にデータ数に対する形態素解析にかかる実行時間とジョブの実行時間を示します。
| データ数 | 形態素解析の実行時間 | ジョブの実行時間 |
|---|---|---|
| 100 | 2秒 | 5分28秒 |
| 1000 | 2秒 | 5分9秒 |
| 10000 | 6秒 | 4分46秒 |
上記の結果から、データ数1万件でも形態素解析にかかった時間は6秒と高速に処理できていることが分かります。 また、調査を行ったデータ数では、ジョブの実行に必要なインスタンスの立ち上げなど、形態素解析の前後の処理に要する時間がジョブの実行時間の殆どを占めており、形態素解析そのものに掛かる時間はごく一部であることが確認できました。 そのため、ジョブの実行時間は、ジョブの実行時に発生する前後の処理に要する時間である約5分をベースにして、データ数に応じた形態素解析にかかる時間の分増加すると予想されます。
実際の運用での注意点
kuromoji-for-bigqueryは、入力テーブルに保存された全ての文書に対して形態素解析を行います。 言い換えると、kuromoji-for-bigqueryは、入力テーブル内の一部のデータを形態素解析して、出力テーブル内の該当データを更新することができません。 しかし、実際の運用では、入力テーブルの一部のデータが更新される、もしくは新しいデータが追加されることがあるため、入力テーブル内で変更があったデータのみに形態素解析を実行したい場面があります。 このように変更が加えられたデータのみ形態素解析の結果を更新する場合は、別途差分の更新を行う実装が必要となります。
まとめ
kuromoji-for-bigqueryを使いGCP上で形態素解析をする方法を紹介し、出力されるBigQuery上のテーブルの確認やCloud Dataflowでのデータ数に対する実行時間の調査と考察を行いました。 データ数に対する実行時間の計測結果は、Cloud Dataflowでkuromoji-for-bigqueryを実行する場合の実行時間の見積もりに役立てることができると思います。
今後は、形態素解析の結果を利用して、筆者が進めている研究「ハンドメイド作品を対象としたECサイトにおける単語の出現頻度を用いた稀覯品検出」のプロダクト実装を進めていくとともに、その他にもサービス改善につながるような用途を探していきたいと考えています。 また、更新が発生したデータのみに対して再度形態素解析を適用するような実装も考えていきたいと思っています。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
