
ペパボ研究所 研究員/シニア・プリンシパルエンジニアの三宅(@monochromegane)です。 本記事では、Googleから発表されたベクトル量子化手法 TurboQuant(arxiv 2504.19874)について、ベクトル検索における量子化の観点から読み解いていきます。ベクトル検索の基礎については、以前開催した「ベクトル検索システムの気持ち」で扱っていますので、興味のある方はそちらもご参照ください。
はじめに
ベクトル検索は、高次元ベクトル空間において、あるクエリベクトルに対して近いベクトル群を見つける近傍探索問題です。RAGを始めとする情報検索や推薦システムにおいて、ベクトル間の距離や内積に基づく類似度計算は中心的な役割を担っています。厳密な近傍探索として、KD-TreeやBall-Treeなどの空間分割に基づくインデックスがありますが、高次元空間では探索効率が急速に低下し、全探索と大差なくなってしまいます。そこで、近似近傍探索(Approximate Nearest Neighbor: ANN)のアプローチが広く用いられています。
ANNの代表的な手法として、ベクトルを圧縮して保持し、近似的な距離計算で高速に検索する量子化ベースの手法があります。素朴には各座標を独立に量子化するスカラー量子化が考えられますが、埋め込みベクトルの座標間には一般に依存関係があり、これを無視すると誤差が蓄積します。ベクトル量子化(Vector Quantization: VQ)は、ベクトル全体を一つの単位としてk-meansでクラスタリングし、最寄りのセントロイド(クラスタの代表値)で代表させることで、座標間の依存関係を保ったまま量子化を行います。しかし、VQの近似精度はクラスタ数に依存し、高次元空間を十分に表現するには多くのクラスタが必要であるため、コードブック(セントロイドの集合)のサイズが指数的に増大します。直積量子化(Product Quantization: PQ)は、ベクトルを複数の部分ベクトルに分割し、それぞれにk-meansを適用することで、この問題を緩和します。
しかし、PQにも課題があります。PQは部分ベクトルの境界で座標間の依存関係を無視しており、どの座標をまとめるかという分割単位は恣意的です。また、データの分布が事前にはわからないため、VQと同様にコードブックの構築にはデータを用いたオフラインでのk-means学習が必要です。もし、データに依存せず、かつ座標ごとに独立に量子化できる方法があれば理想的です。すなわち、全座標が同じ既知の分布に従うような変換を施し、その分布に対して最適なスカラー量子化器を一度設計すれば、全座標・全ベクトルに適用できます。
TurboQuantは、まさにこの理想を実現する方式の一つです。ランダム回転によって各座標を同一の既知の分布に従わせ、その分布に最適化されたセントロイドで量子化を行います。なお、TurboQuantはデータ非依存のオンライン量子化であるため、KVキャッシュの圧縮にも適用可能です。本記事ではベクトル検索への応用を中心に据えますが、手法の汎用性も念頭に置いて読み進めてください。
TurboQuant
「望ましい」ベクトルへの変換
TurboQuantの出発点は、量子化に都合のよいベクトルへの変換です。
まず、元のベクトルをL2正規化して単位球面 \(\mathbb{S}^{d-1}\) 上に配置します。この正規化されたベクトルを \(\boldsymbol{x}\) とします。次に、ランダム直交行列 \(\Pi\) を用いて回転を施します。
\[\boldsymbol{y} = \Pi \cdot \boldsymbol{x}\]ここで \(\Pi\) は、各要素が独立に標準正規分布に従うランダム行列にQR分解を適用して生成します。この方法で得られる直交行列は、全ての方向を等しく扱う一様にランダムな回転を与えます。そのため、任意の固定単位ベクトル \(\boldsymbol{x}\) に対して \(\Pi \cdot \boldsymbol{x}\) は球面上の一様分布になり、元のベクトルがどの方向を向いていても、回転後の各座標は同じ分布に従います。
下図は、\(d=64\)において方向の異なる3つの入力ベクトルに対して、毎回新たに生成した同一の回転行列を3つのベクトルに適用する試行を10,000回繰り返し、回転後の座標1, 2, 64のヒストグラムを示したものです。入力ベクトルの方向によらず、いずれの座標も同一の分布(黒破線)に従っていることが確認できます。
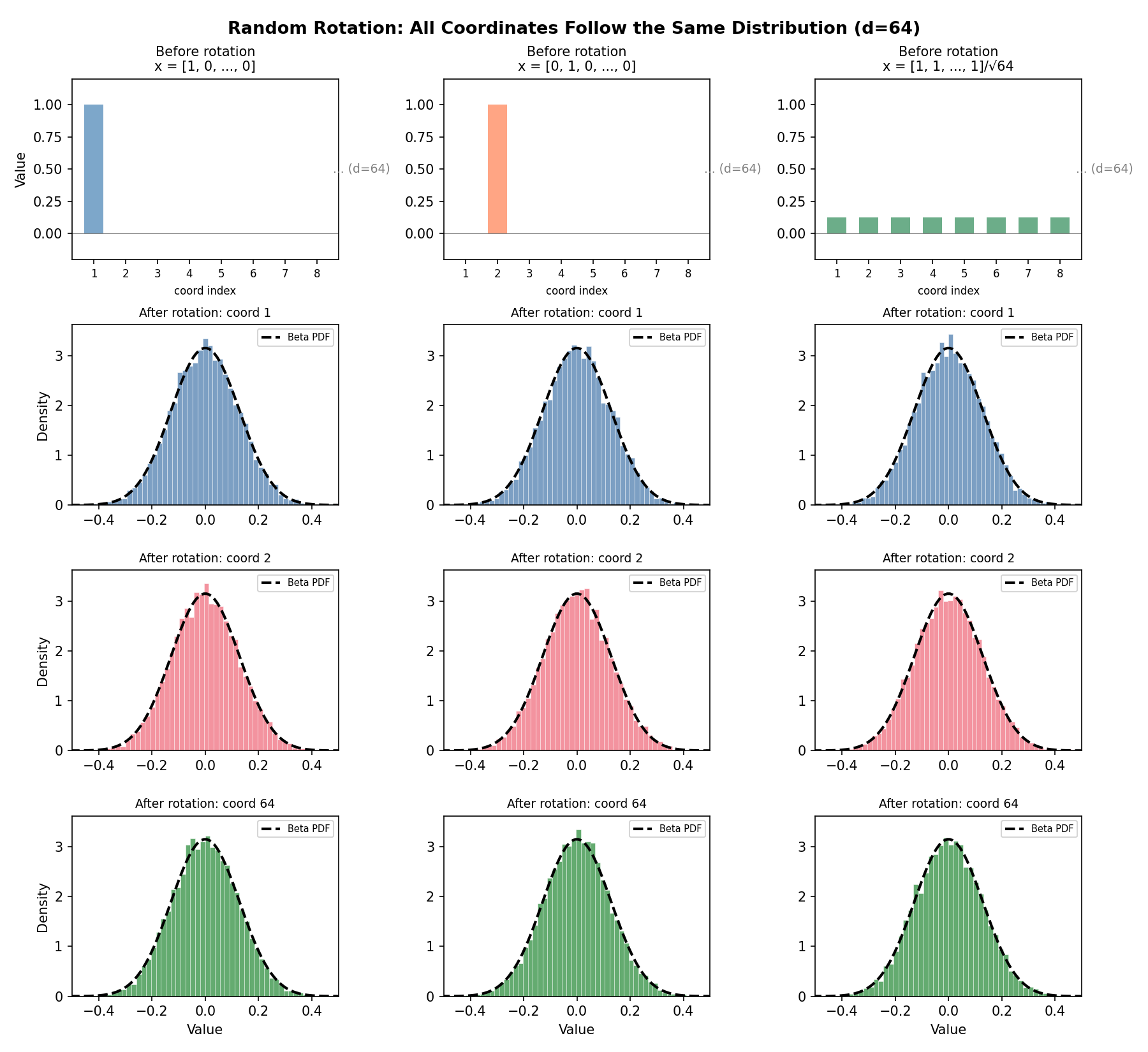
厳密には、球面上の一様分布では座標間に \(x_1^2 + \cdots + x_d^2 = 1\) という制約があるため、座標は独立ではありません。しかし、高次元では各座標が全体の \(1/d\) の情報しか持たないため、他の座標への影響が無視できるほど小さくなります。TurboQuantでは、この高次元での「近似的な独立性」を仮定として採用し、座標ごとに独立にスカラー量子化を適用します。
各座標の分布
前節で、回転後の各座標は同一の分布に従うことを確認しました。では、その分布はどのような形をしているのでしょうか。球面上に「一様に」分布する点の座標なのだから、各座標も一様に分布しそうに思えますが、必ずしもそうではありません。
論文のLemma 1によると、\(d\) 次元単位球面上に一様分布する \(\boldsymbol{x}\) の \(j\) 番目の座標 \(x_j\) は、以下の分布に従います。これは標準Beta分布(定義域 \([0,1]\))を \([-1,1]\) にスケール・シフトしたもので、パラメータ \(\alpha = \beta = (d-1)/2\) の対称な分布です。
\[f_X(x) = \frac{\Gamma(d/2)}{\sqrt{\pi}\,\Gamma((d-1)/2)} \left(1-x^2\right)^{(d-3)/2}, \quad x \in [-1, 1]\]この分布がどのように導かれるか、概要を見ていきます。d=3(通常の球面)を例に考えます。\(\boldsymbol{x}\) が球面上に一様分布するとき、ある座標 \(x_1\) が 0.8 から 0.9 の間に入る確率はどう求められるでしょうか。球面上で \(x_1 \in [0.8, 0.9]\) に対応する領域は、球面を輪切りにした「帯」になります。この帯の面積を球面全体の面積で割れば確率を求めることができそうです。
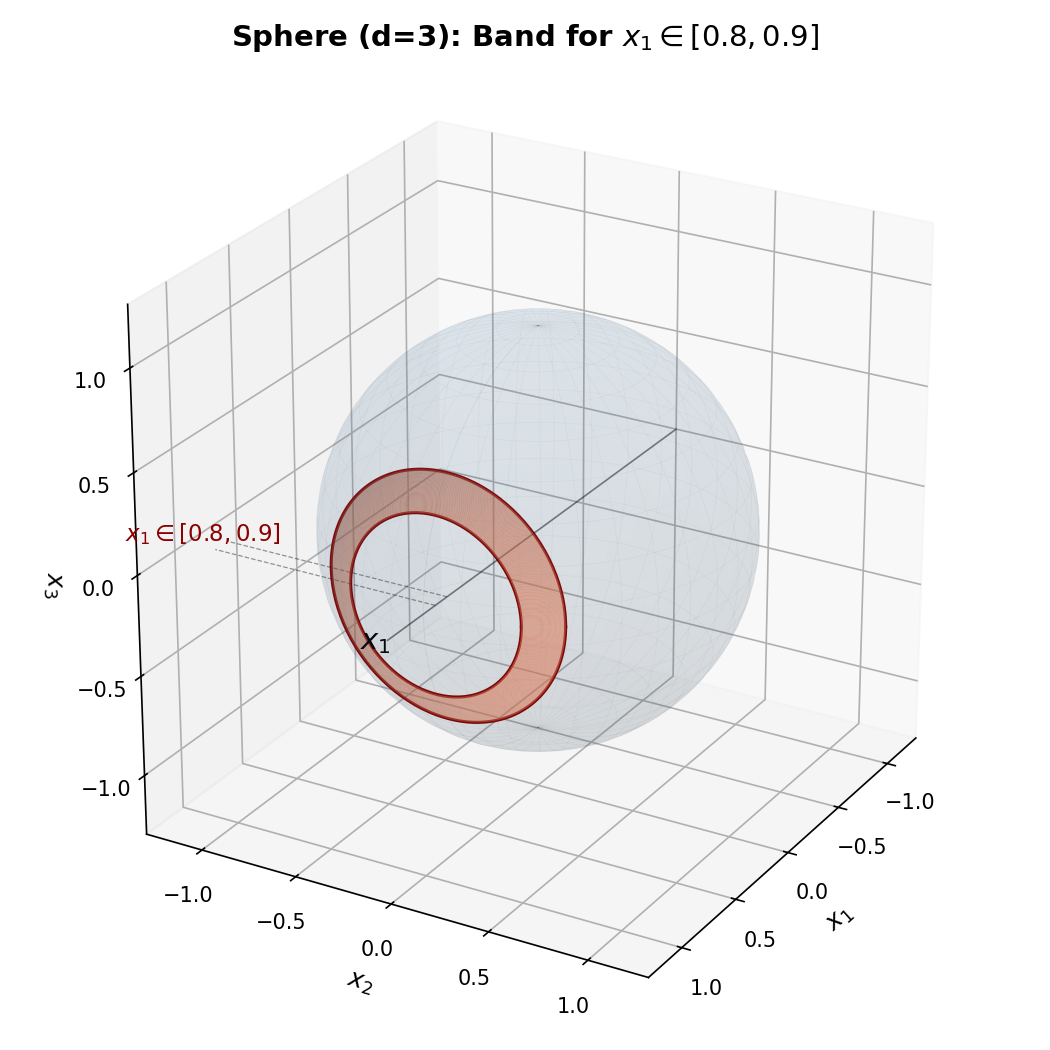
では、帯の面積はどう決まるでしょうか。帯の面積は「断面の大きさ × 帯の幅」に分解できます。以下ではこの2つの要素を順に見ていきます。
断面の大きさ
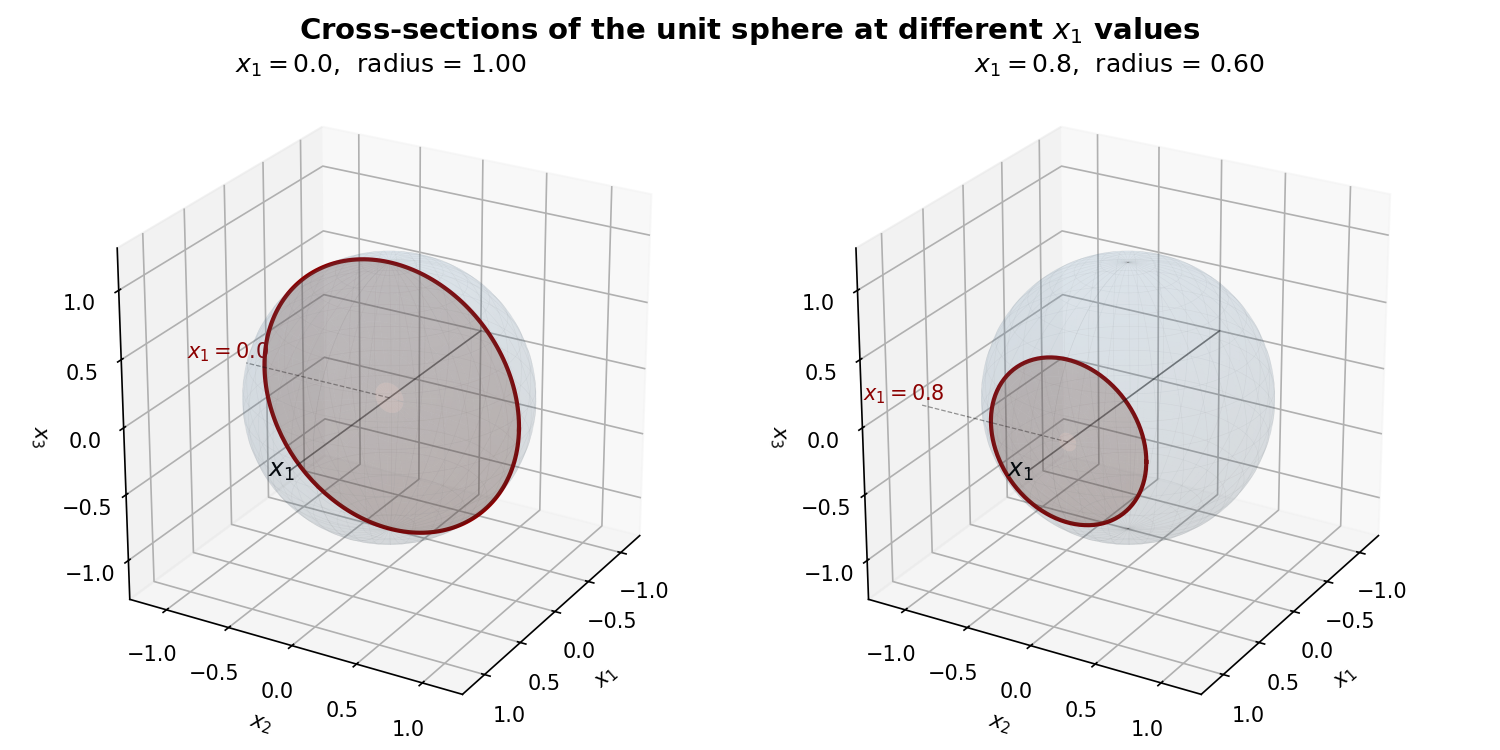
球面を \(x_j = x\) でスライスすると、残りの \(d-1\) 個の座標は \(x_1^2 + \cdots + x_{j-1}^2 + x_{j+1}^2 + \cdots + x_d^2 = 1 - x^2\) を満たします。これは半径 \(\sqrt{1-x^2}\) の球面です。例えば d=3 の球面を \(x_1 = x\) でスライスすると、残り2つの座標が成す断面は円になります。d=4 の場合は残り3つの座標が成す断面は球面になります。一般の \(d\) では断面の表面積は半径の \((d-2)\) 乗に比例するので、半径 \(\sqrt{1-x^2}\) を代入すると:
\[\text{断面の大きさ} \propto \left(\sqrt{1-x^2}\right)^{d-2} = (1-x^2)^{(d-2)/2}\]具体的に d=3(通常の球面)で考えると、断面は円なので大きさは半径に比例し、 \((1-x^2)^{(3-2)/2} = \sqrt{1-x^2}\) です。\(x_1 = 0\) なら \(\sqrt{1-0} = 1\)、\(x_1 = 0.8\) なら \(\sqrt{1-0.64} = 0.6\) となり、端に近いほど断面が小さくなります。
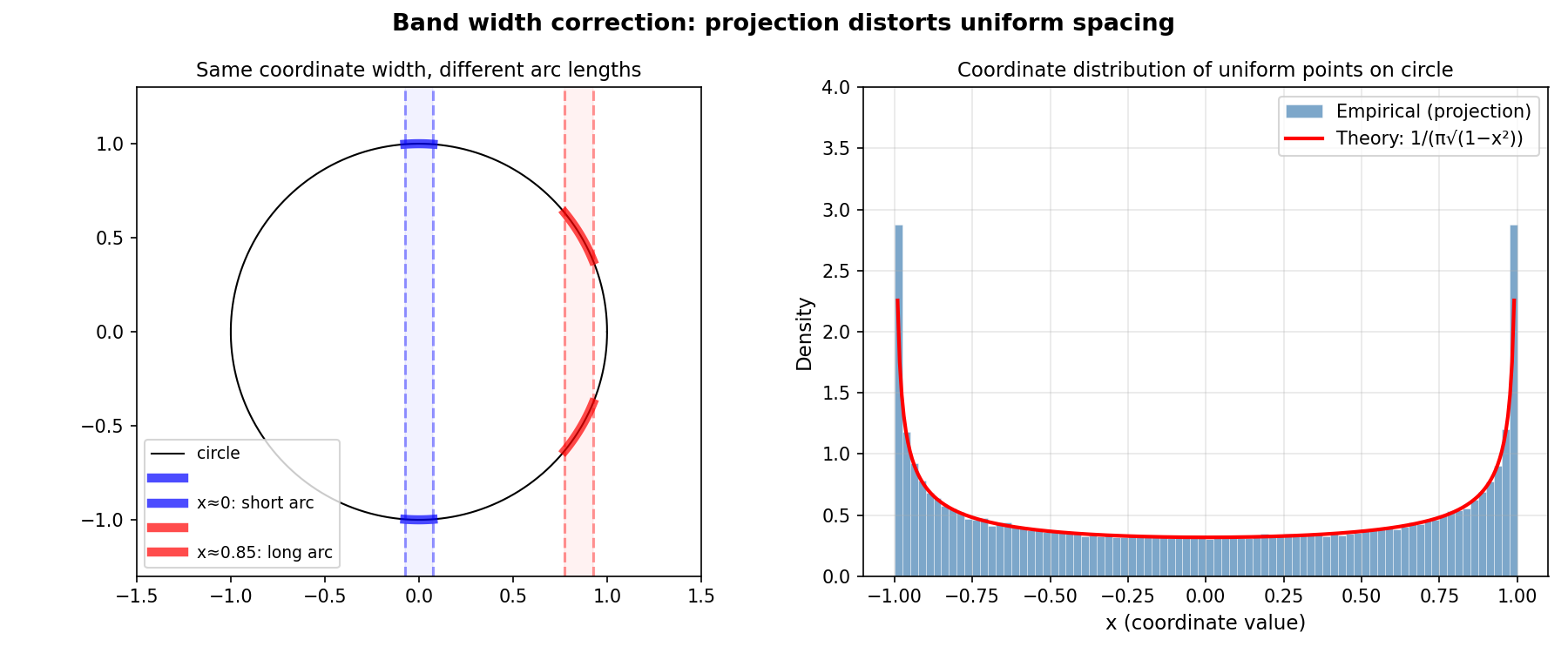
帯の幅
帯の幅は座標軸上の幅ではなく、球面上の弧の長さです。座標軸上で同じ幅を取っても、球面上での弧の長さは場所によって異なります。円周上の微小な移動は、十分に拡大すれば横(座標軸方向)、縦(それに垂直な方向)、斜辺(弧の長さ)の直角三角形と見なせるため、ピタゴラスの定理から、座標値 \(x\) 付近での微小な弧の長さは座標軸上の幅に対して \(1/\sqrt{1-x^2} = (1-x^2)^{-1/2}\) 倍になります。下図左は円(d=2)の場合ですが、\(x \approx 0\) 付近(青)と \(x \approx 0.85\) 付近(赤)で同じ座標幅を取ると、端に近いほど対応する弧が長くなることがわかります。下図右は、円周上に一様にランダムな点を大量に生成し、その\(x\)座標の分布をヒストグラムにしたものです。円周上では均等に分布しているにもかかわらず、\(x\)座標で見ると端(\(\pm 1\))付近に集中していることがわかります。なお、赤線は理論的な確率密度 \(1/(\pi\sqrt{1-x^2})\) で、\(1/\sqrt{1-x^2}\) を全区間で積分すると \(\pi\) になるため正規化定数として \(1/\pi\) が掛かっています。
帯の表面積から確率密度へ
最初に述べたように、座標値 \(x\) 付近の確率は帯の面積に比例し、帯の面積は「断面の大きさ × 帯の幅」です。それぞれを式にすると、Lemma 1の \((1-x^2)^{(d-3)/2}\) が現れます:
\[f(x) \propto \underbrace{(1-x^2)^{(d-2)/2}}_{\text{断面(0に集中させる力)}} \times \underbrace{(1-x^2)^{-1/2}}_{\text{帯の幅(±1に集中させる力)}} = (1-x^2)^{(d-3)/2}\]ここで \(\propto\) は正規化定数を省略していることを意味します。Lemma 1の式にあるガンマ関数の係数 \(\Gamma(d/2) / (\sqrt{\pi}\,\Gamma((d-1)/2))\) は、全区間で積分して1になるように定まる正規化定数です。
なお、d=3 ではこの二つの力がちょうど釣り合い、座標の分布は一様になります。冒頭で「各座標も一様に分布しそう」と述べた直感は d=3 では正しいのですが、高次元では断面の力が支配的になり、分布は0付近に鋭く集中します(\(\mathcal{N}(0, 1/d)\) に収束)。このLemma 1を通しての重要な気づきは、ベクトル検索やTransformerのチャネル数として典型的な次元数(\(d \geq 64\) など)では、等間隔にセントロイドを配置する一様量子化が非効率であるということです。
最適セントロイド: Lloyd-Maxアルゴリズム
分布が分かったので、\(b\) ビットの最適なスカラー量子化器を設計できます。区間 \([-1, 1]\) を \(2^b\) 個のクラスタに分割し、MSE(平均二乗誤差)を最小化するセントロイドの配置を求めます。この最適化問題を解くのがLloyd-Maxアルゴリズム(PDF)です。以下の2ステップを交互に繰り返します。
境界更新: 隣り合うセントロイドの中点に境界を置く
\[b_i = \frac{c_{i-1} + c_i}{2}\]セントロイド更新: 各区間内の条件付き期待値にセントロイドを移動する
\[c_i = \frac{\int_{b_i}^{b_{i+1}} x \cdot f_X(x) \, dx}{\int_{b_i}^{b_{i+1}} f_X(x) \, dx}\]分母はその区間にデータが入る確率、分子は位置と出やすさの積です。割り算の結果は、その区間に限定した場合の期待値、すなわち条件付き期待値になります。反復は数回〜十数回で収束します。コードブックは分布とビット幅が決まれば一度だけ計算すればよく、事前に計算して保存しておけます。
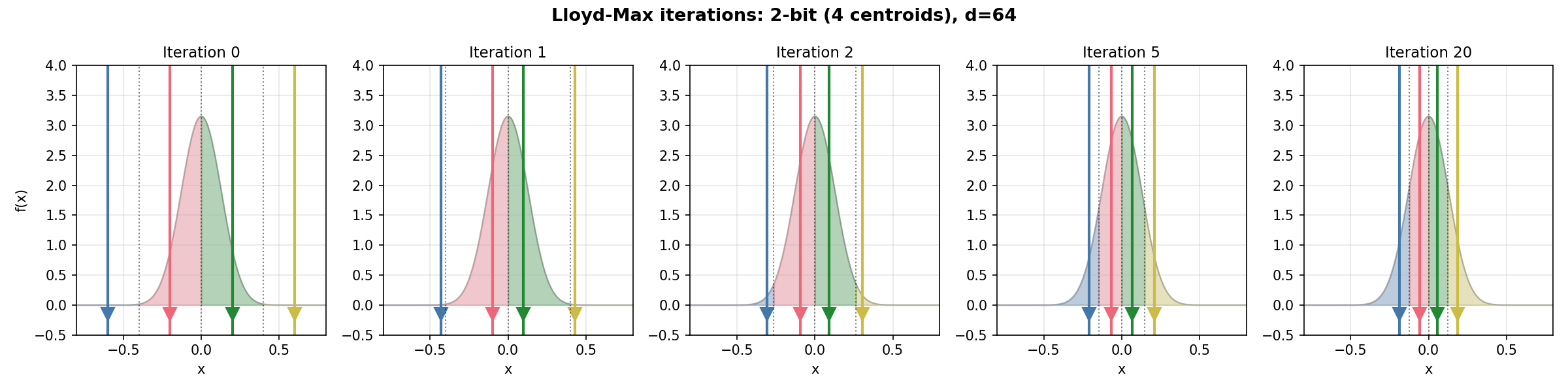
上図の反復0回目は等間隔にセントロイドを配置した一様量子化に相当します。反復が進むにつれて、データが集中する0付近にセントロイドが密に再配置されていく様子から、この分布に対してLloyd-Maxによって得られる量子化が一様量子化より効果的であることがわかります。
ベクトル検索への適用
TurboQuantをベクトル検索に適用する際の利点を、PQとの比較を軸に整理します。
導入の容易さ
PQはデータセットに対してk-meansでコードブックを学習するため、部分空間の分割数やセントロイド数といった設計選択が必要であり、データが変わればコードブックの再学習も求められます。また、k-meansは局所最適解への収束しか保証されないため、結果が初期値に依存します。TurboQuantではコードブックがデータに依存せず、ビット幅を決めれば既知の分布に対する1次元の最適化で済みます。論文の実験では、10万件・4ビット量子化において、PQの量子化時間が次元数に応じて37〜494秒であるのに対し、TurboQuantは0.001秒程度と報告されています。
小さいルックアップテーブル
ベクトル検索では、クエリの値とセントロイドとの距離を事前に計算したルックアップテーブルがよく用いられます。PQでは部分空間ごとにセントロイドが異なるため、部分空間の数だけテーブルが必要です。TurboQuantでは全座標が同じ \(2^b\) 個のセントロイドを共有するため、テーブルは1つで済みます。\(b = 4\) の場合、わずか16エントリです。さらに、回転は内積を保存するため、クエリ自体も同じ方法で量子化できます。この場合でもセントロイド間の積を格納する \(2^{2b}\) エントリ(\(b = 4\) で256)のテーブルを事前に一度だけ計算すれば、テーブル参照と足し算だけで内積が求まります。
実際に、Redisの作者として知られるantirezがRedis Vector SetsにTQ4を実装し、同じ4ビットのQ4(recall 92.24%)に対して94.39%を達成したことが報告されています。同じ4ビットならTQ4を採用しない理由はないという趣旨の評価がなされています。
おわりに
本記事を通じて、TurboQuantの数学的枠組みの格好良さと、そこから生まれる汎用性・実用性の高さを感じていただけたら嬉しく思います。球面上への配置とランダム回転で扱いやすい形に変換し、その座標の分布を正確に導出し、古典的なLloyd-Maxアルゴリズムで最適なセントロイドを求める。各ステップが前のステップの上に自然に積み上がっていく構成は、理論と実用の間を綺麗に橋渡ししていると感じました。
なお、論文ではMSE最適化に加えて、QJL(Quantized Johnson-Lindenstrauss)変換を用いた不偏な内積推定の拡張も提案されています。興味のある方はぜひ論文をご参照ください。
TQ4程度のビット幅であれば実用的な効果が見込めること、そして実装が容易であること(共通コードブック、学習データ不要)から、TurboQuantの方式は今後さらに広まっていくのではないかと考えています。
ペパボ研究所では、今後もベクトル検索や関連する分野において、気になる手法を紹介していきます。
ペパボ研究所では、AI体験の実現に向けて「なめらかなシステム」というビジョンのもと研究開発を進めています。本記事や関連する取り組みに興味を持たれた方は、ぜひお声がけください。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
