
ペパボ研究所 研究員/プリンシパルエンジニアの三宅(@monochromegane)です。
2025年8月、OpenAIよりオープンウェイトモデルとしてgpt-ossが公開されました。 これらのモデルは、軽量ながら既存の強力なモデルに匹敵する性能を示しており、gpt-oss-120bはo4-miniと、gpt-oss-20bはo3-mini と同水準のベンチマーク結果を達成したと報告されています。 また、これらはApache 2.0ライセンスのもとで提供され、単一GPUで効率的な推論が可能である点が特徴として示されています。 こうした特性は、AI施策のコスト削減や適用範囲の拡大に寄与すると見込まれ、多くの組織で関心を集めていると想像されます。
一方で、サービス環境におけるこれらの言語モデルの導入には、モデルの出力精度や生成内容の妥当性だけでなく、サービング時のリクエスト処理性能が重要な要素となります。 処理性能はモデルのサイズに依存するだけでなく、使用するGPUの種類、入力および出力トークン数、さらにReasoning effortを設定可能なリーゾニングモデルにおいては、その指定値によっても大きく変動します。
また、実サービス環境では、シンプルな直列処理によるローカル推論とは異なり、複数リクエストを同時に処理する並列化の効率も考慮する必要があります。 並列化の仕組みとその性能は、ユーザー体験やシステムのスケーラビリティに直結するためです。
本評価では、これらの条件を踏まえ、異なるGPU環境におけるgpt-ossモデルのリクエスト処理性能を測定し、サービング時の適切な設定方針を明らかにすることを目的とします。
評価の環境
本評価では、複数のGPU環境における比較が必要であるため、下記のGPUインスタンスを提供するクラウドサービスとしてGoogle CloudのCompute Engineを利用しました。 GPUの選定にあたっては、OpenAIがgpt-oss-120bの起動に最低限望ましいとするHopperアーキテクチャのNVIDIA H100を用いるとともに、一世代前のアーキテクチャではあるもののVRAM要件を満たしつつ稼働コストの削減が見込まれるNVIDIA A100およびNVIDIA L4を、それぞれ120bおよび20bモデルの検証対象として採用しました。
利用したインスタンスタイプは以下の通りです。
- a3-highgpu-1g(26 vCPU, 234 GB メモリ, 1 × NVIDIA H100 80GB)
- a2-ultragpu-1g(12 vCPU, 170 GB メモリ, 1 × NVIDIA A100 80GB)
- g2-standard-4(4 vCPU, 16 GB メモリ, 1 × NVIDIA L4 24GB)
いずれのインスタンスも標準提供されているDebian GNU/Linux 12 (bookworm)をブートイメージとして利用し、GPU関連についてはNVIDIAから提供されているcuda-toolkit-12-8およびcuda-drivers-570を別途導入しました。
なお、評価期間中のコストを抑制するため、すべてのインスタンスはSpotインスタンス として稼働させています。
評価の方法
本評価では、リクエスト処理性能に影響を与えると予想される要素として、GPU種別、モデル種別、プロンプトのトークン数、Reasoning effort の設定値(low, medium, high)、並列リクエスト数(1, 2, 4, 8, 16)を組み合わせ、その違いによって指標にどのような変化が生じるかを確認しました。 評価指標には、秒間リクエスト数(Requests per second: RPS)とレスポンス時間を採用しました。
プロンプトについては、自社の想定ユースケースに近い内容をもとに、約2,000、4,000、8,000トークン程度となるよう調整しました。 これらはテンプレートから動的に生成し、それぞれ5,000パターンを用意しています。実験時には、この中からランダムに選択しました。
モデルのサービングには、高速推論ライブラリであるvLLMを用いました。vLLMはPagedAttentionやcontinuous batchingなどの仕組みにより高い並列性を実現しており、サービス導入を視野に入れた推論サーバーとして本評価に採用しました。
起動オプションについては、公式レシピに従い --async-schedulingを付与しました。
また、H100上でgpt-oss-120bを利用する際にはVRAM容量の制約から最大トークン数を109,504未満に抑える必要があったため、評価環境を統一する観点から、すべての環境において--max-model-len=100000を指定しました。
さらに、A100およびL4環境では前世代のアーキテクチャでの起動をサポートするためTRITON_ATTN_VLLM_V1をattention backendとして指定しました。
負荷試験には、オープンソースの負荷試験ツールLocustを使用しました。
各条件の組み合わせごとに120秒間の試験を行い、Locustの出力値のRequests/sとMedian Response Timeを採用しました。
評価の結果
H100環境におけるリクエスト処理性能
以下の図1,2に、H100上でgpt-oss-20bおよびgpt-oss-120bを実行した際のリクエスト処理性能を示します。
図1: レスポンス時間の変化
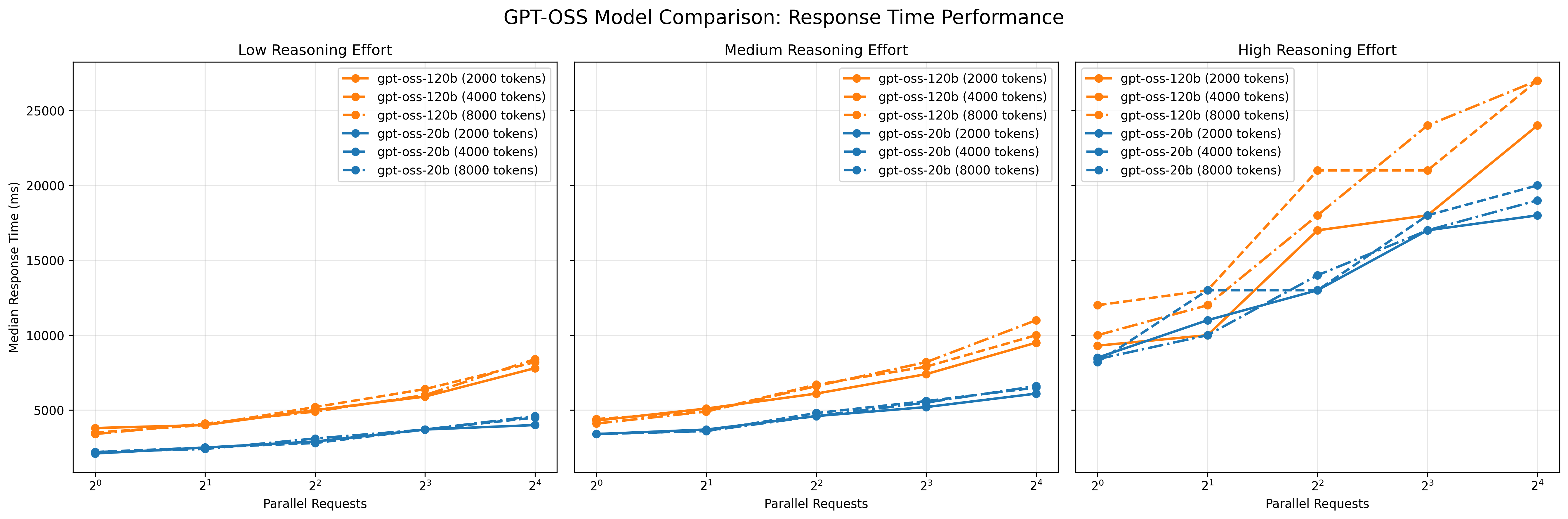
図2: 秒間リクエスト数の変化
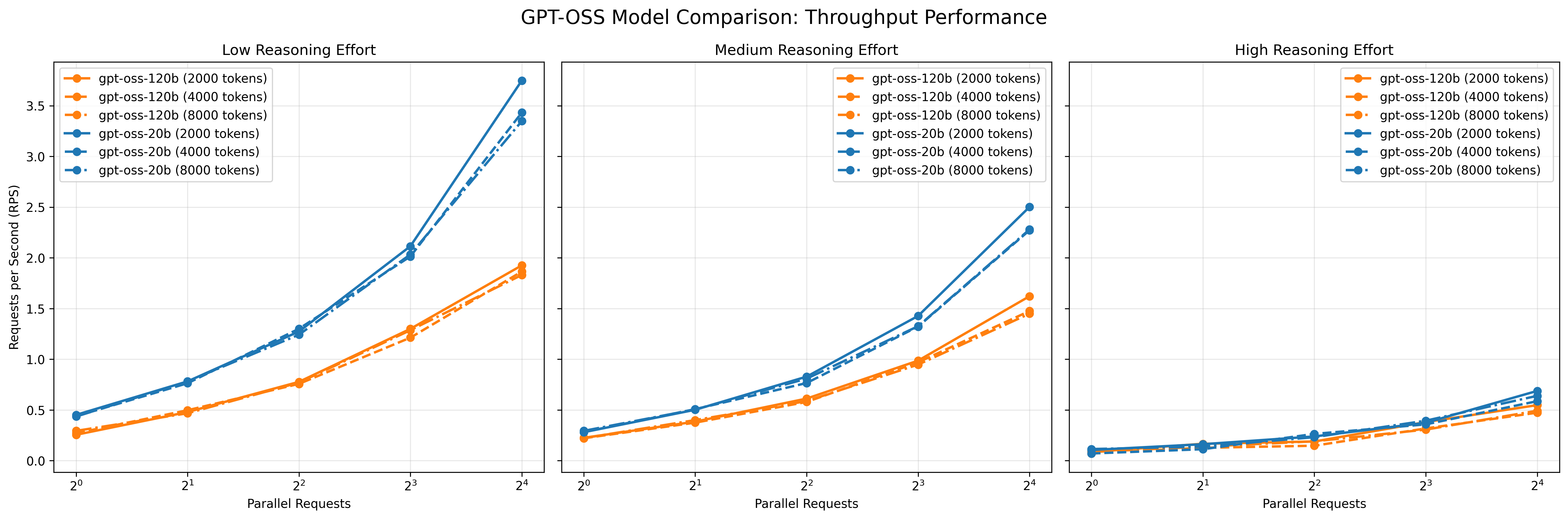
これらの図は、リクエスト並列数、入力トークン数、Reasoning effort の各条件を組み合わせた場合におけるレスポンス時間の中央値および秒間リクエスト数(RPS)の変化を表しています。 図より、以下の傾向が読み取れます。
- リクエスト並列数の増加による影響: 並列数の増加に伴い、いずれの条件においてもレスポンス時間は増加し、RPSは緩やかに上昇しました。特に低~中程度の負荷条件(Reasoning effort が low〜medium、かつ20bモデル)では、vLLMの並列処理機構が有効に機能している様子が見られました。
- Reasoning effortの影響: Reasoning effortの設定値をlowからhighに上げると、レスポンス時間が顕著に増加し、RPSは低下しました。これはモデル内部の推論負荷が増すことで、並列化による効果が打ち消されやすくなるためと考えられます。
- モデルサイズの影響: gpt-oss-120bはgpt-oss-20bに比べ、全体的にレスポンス時間が長く、RPSが低い傾向にありました。ただしその差は2倍以上にはならず、モデル規模の拡大に比して処理性能の低下は比較的緩やかであることが確認されました。
- 入力トークン数の影響: 入力トークン数を増加させても、処理性能への影響は相対的に小さく、Reasonig effortやモデルサイズに比べて副次的な要因にとどまりました。
これらの傾向から、H100 環境では推論負荷の低い条件下でvLLMの並列処理機構の恩恵が大きく表れる一方、推論負荷が高い場合(Reasoning effort high × 120bなど)には並列化の効果が限定的であることが示されました。
出力トークン数の影響分析
レスポンス時間の比較では、gpt-oss-20bとgpt-oss-120bの差は2倍未満にとどまっていました。 これをトークン出力あたりの時間の差とみなせるならば、モデルサイズよりも出力トークン数が処理性能に与える影響を検証することが重要と考え、追加分析を行いました。
ここで、Reasoning effortの設定によってReasoning部分の出力トークン数が変化することを踏まえ、モデルごとの出力傾向を確認します。 まず、出力トークン数の生成傾向をモデル別およびReasoning effortごとに比較するため、4000トークンの入力に対応するプロンプトのうち500パターンについて出力トークン数の統計を求めました。 結果を図3に示します。
図3: 出力トークン数の変化
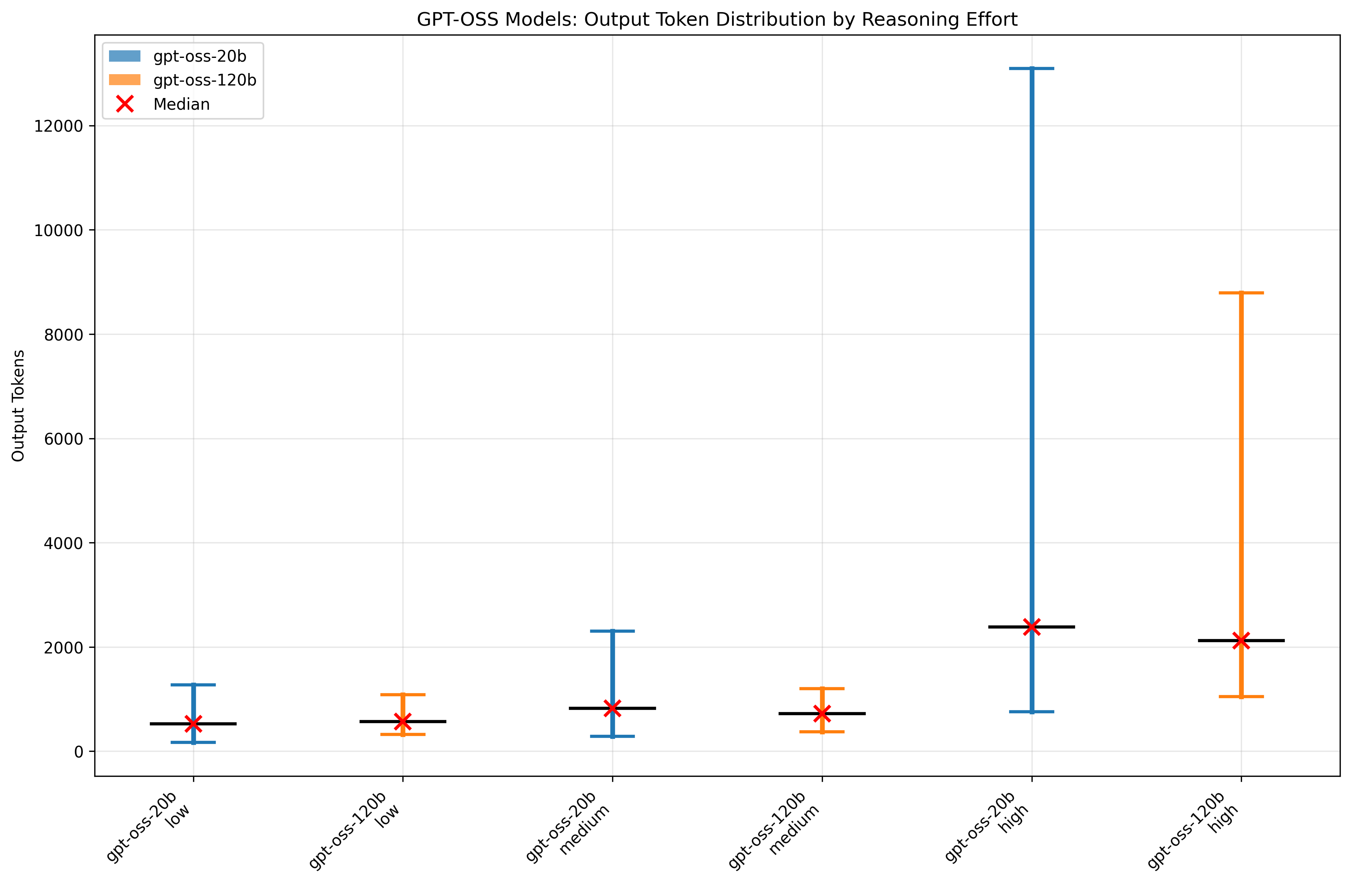
このプロットでは最小値、最大値、平均値、中央値を示しています。 平均値の観点では、両モデルともReasoning effortがlowおよびmediumの場合に大きな差はなく、highの場合に出力量が増加しました。 モデル同士を比較すると、各Reasoning effortにおいてほぼ同程度の出力量が得られ、必ずしも120b が多いわけではなく、場合によっては 20b が上回ることもありました。 一方で、大きな出力量への上振れは20bの方が顕著でした。 すなわち、本評価条件においては、モデル間のレスポンス時間差は出力量そのものではなく、トークンあたりの推論時間に起因すると考えて良さそうです。
続いて、出力トークン数とレスポンス時間の関係を分析するため、出力トークン数を 100, 200, 400, 800 に制限して同一条件下でベンチマークを行いました(並列数 1、Reasoning effort medium、入力トークン数 4000)。 結果を図4に示します。
図4: 出力トークン数制限によるレスポンス時間の変化
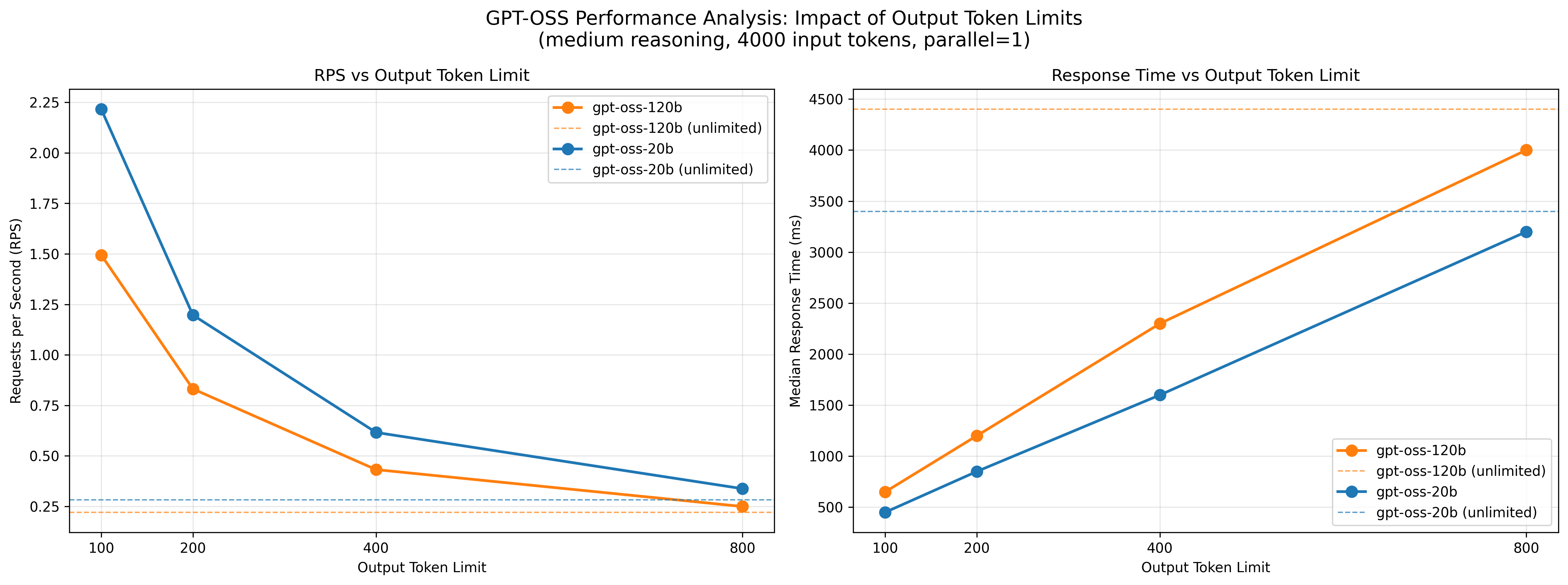
結果から、リクエスト処理性能は出力トークン数に強く依存することが明らかとなり、レスポンス時間の抑制には出力トークン数の制御が有効であると分かりました。 さらに、リクエスト処理性能と推論精度を両立する観点からは、小さいモデルでReasoning effortをhighにするよりも、大きいモデルでmediumを用いたり、最大出力長を適切に制御する方が応答性能の安定化に寄与すると考えられます。
A100およびL4環境におけるリクエスト処理性能
以下の図5〜8にA100上でgpt-oss-120bを、L4上でgpt-oss-20bをそれぞれ実行した結果を示します。 なお、先に述べたとおり入力トークン数の影響は相対的に小さいため、本評価では入力トークン数を4000に固定してベンチマークを実施しました。 また、比較のためH100上での同条件の結果も併記しています。
図5: A100とH100でのレスポンス時間の比較
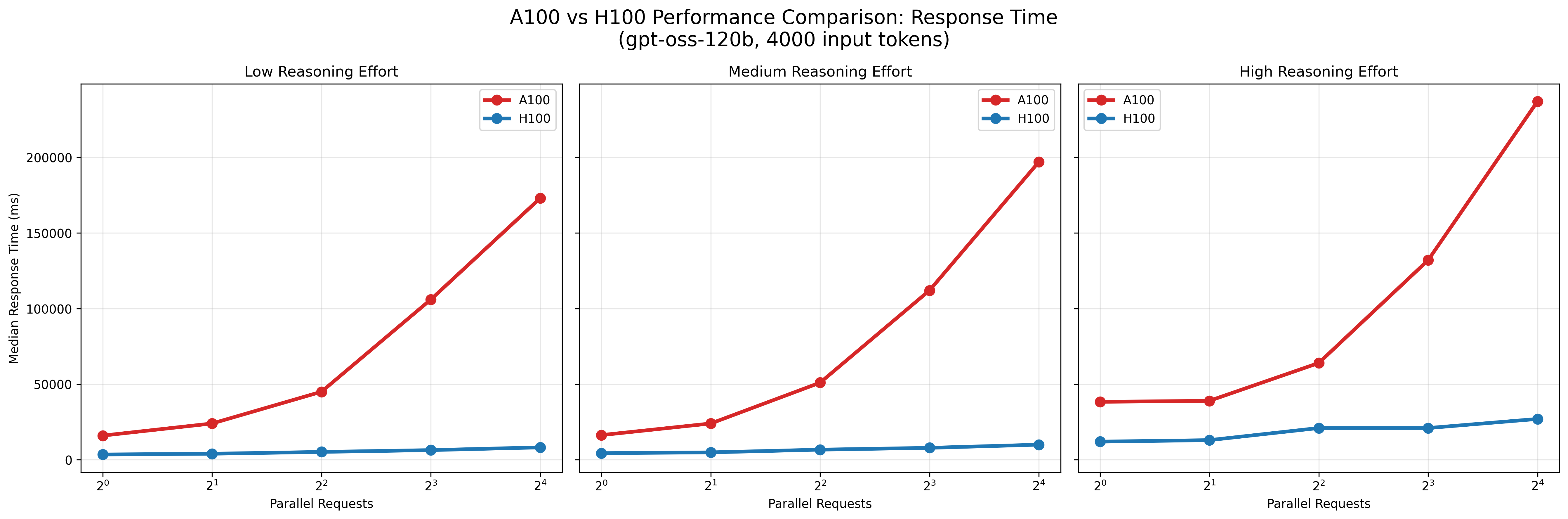
図6: A100とH100での秒間リクエスト数の比較
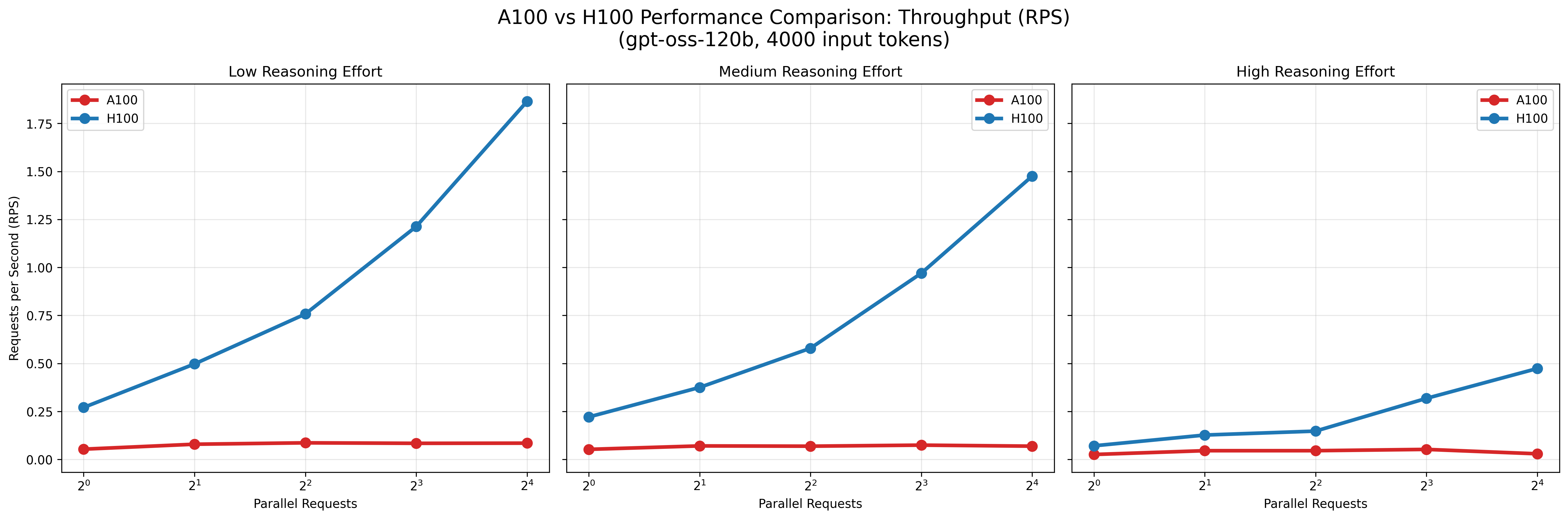
図7: L4とH100でのレスポンス時間の比較
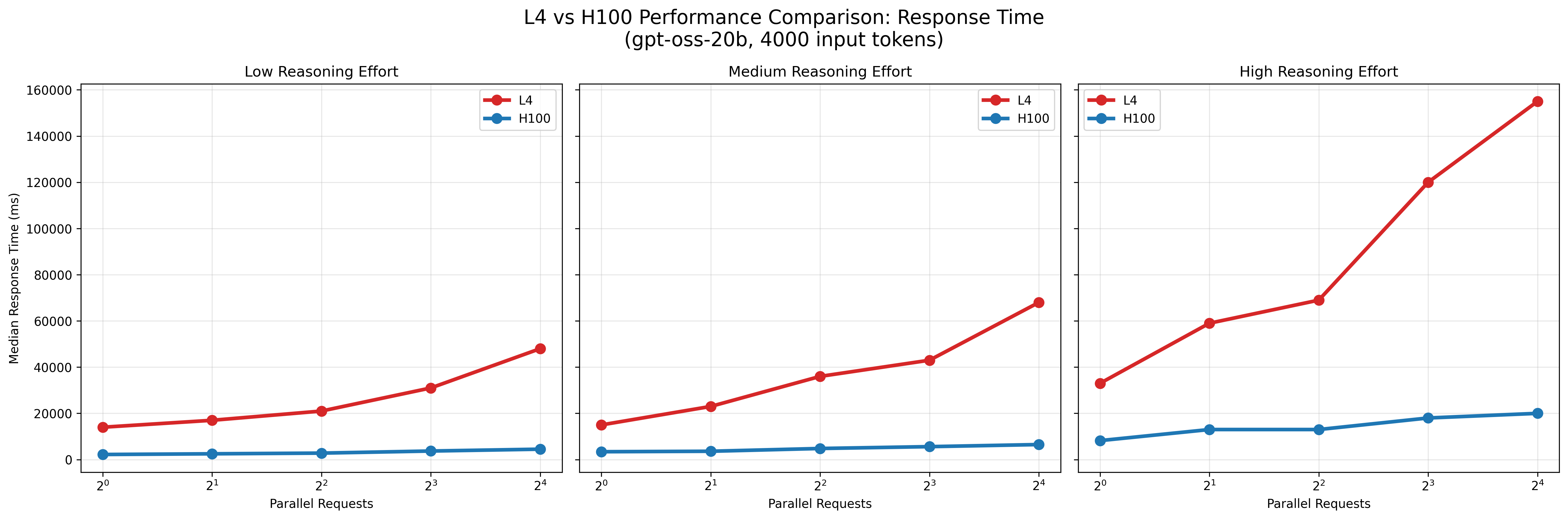
図8: L4とH100での秒間リクエスト数の比較
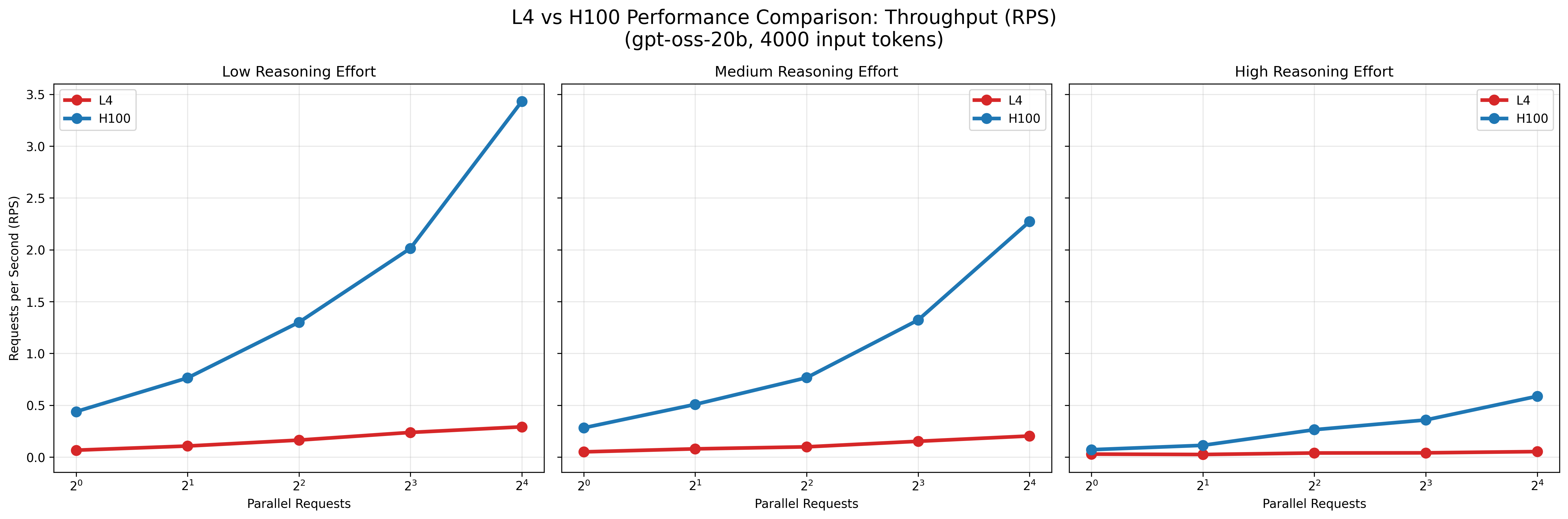
結果として、A100およびL4環境はいずれもモデルの推論実行は可能でしたが、H100と比較して応答時間が大幅に長く、並列数を増加させてもスループットはほとんど改善しませんでした。 すなわち、これらの環境は少数リクエストの処理には利用可能である一方、大規模な並列処理やサービス用途でのgpt-ossの安定運用には適さないと考えられます。
まとめ
本報告では、言語モデルgpt-ossを対象として、GPU環境や推論サーバー構成がリクエスト処理性能に与える影響を評価しました。 その結果、サービス用途での安定運用にはH100以上の環境が望ましく、また適切な推論サーバーを導入することで並列数の増加に応じたスループット向上が可能であることを確認しました。 さらに、リクエスト処理性能の改善には、モデルサイズのみならずReasoning effortの選定や出力トークン数の制御が有用であることを明らかにしました。 これらの結論は、提供元の推奨やモデルの推論機序に照らせば妥当なものである一方、実測によって裏付けられたことで、導入に際して根拠ある選定基準を得ることができました。
ペパボ研究所では、研究開発組織としての立場から、今後も研究に加えてこのような実応用を見据えた評価を報告し、導入や運用に関する知見も公開していきたいと考えています。
Appendix
以下に、本評価に関連する具体的な手順等を記載します。
推論サーバーの構築手順
NVIDIAドライバのインストール
$ wget https://developer.download.nvidia.com/compute/cuda/repos/debian12/x86_64/cuda-keyring_1.1-1_all.deb
$ sudo dpkg -i cuda-keyring_1.1-1_all.deb
$ sudo apt update
$ sudo apt install -y linux-headers-$(uname -r) cuda-toolkit-12-8 cuda-drivers-570
$ sudo reboot
Python環境とvLLMのインストール
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ source $HOME/.local/bin/env
$ uv venv --python 3.12 --seed
$ source .venv/bin/activate
$ uv pip install --pre vllm==0.10.1+gptoss --extra-index-url https://wheels.vllm.ai/gpt-oss/ --extra-index-url https://download.pytorch.org/whl/nightly/cu128 --index-strategy unsafe-best-match
gpt-ossモデルのサービング
# H100
$ vllm serve openai/gpt-oss-120b --max-model-len=100000 --async-scheduling
# A100, L4
$ VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 vllm serve openai/gpt-oss-120b --max-model-len=100000 --async-scheduling
トラブルシューティング
Spotインスタンスの停止後、次の起動時にOSがGPUを認識しなくなる現象が発生しました。
原因は、OSのバージョンアップにより、バージョンに対応するヘッダーファイルが見つからなくなるためです。
この場合、sudo apt install linux-headers-$(uname -r)を実行後、再起動により再度認識されるようになります。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
