
研究員の @zaimy です。ペパボ研究所では、自社が運営するウェブサービスのユーザーの行動ログや属性情報を収集・分析・活用するための全社基盤「Bigfoot」を技術基盤チームと協力して開発・運用しています。 Treasure Data をバックエンドとして2016年に運用を開始したこのシステムを、今年 Google Cloud Platform(以下 GCP)を中心とした構成に移設しました。この記事では移設に至った理由、移設時の工夫、移設後の構成などについてお話します。
目次
Bigfoot とは
Bigfoot は、ウェブサービスに関する様々なデータを扱う基盤です。現在は行動ログや属性情報だけでなく、ペパボが出稿したウェブ広告のデータやユーザーからのお問い合わせデータなども蓄積しており、データウェアハウスを中心にデータを活用するための仕組みを整備しています。DX Criteria 1 の1テーマとして挙げられている「データ駆動」を推進していくためにも、今後 Bigfoot は更に重要になっていくと考えています。
移設前の構成と移設に至った経緯
従来 Bigfoot はフルマネージドの Customer Data Platform である Treasure Data をバックエンドにしていました。Treasure Data は、fluentd などでデータを送るとスキーマレスにデータが格納されるため、基盤の立ち上げ期において、どのようなスキーマがログの活用に適しているのか分からない状況で試行錯誤していく上で、非常に便利でした。また、他の SaaS からデータをインポートする機能も充実しており、広告プラットフォームや Google Analytics からのデータを開発なしで Bigfoot に統合することもできました。格納したデータは Hive や Presto などで SQL ライクに操作することができるため、データの利用者の学習コストも比較的低く、DSL などへのロックインもありません。ワークフローエンジンの Digdag もマネージドな環境で提供されているため、データを Treasure Data に送る仕組みや、送ったデータを分析・活用するためのワークフローの開発・運用に集中することができました。
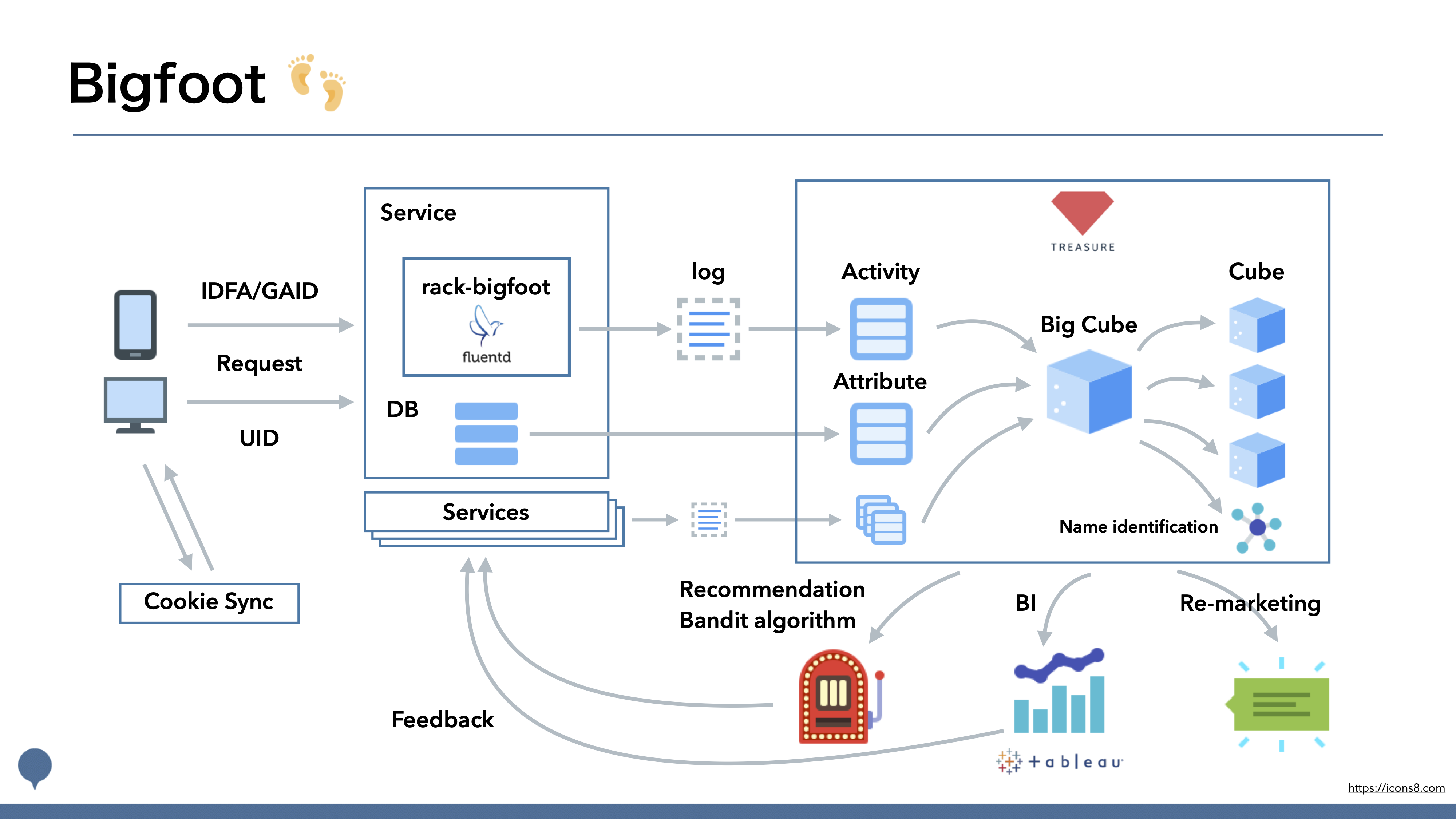 2016年の Bigfoot の構成(出典: サービスに寄り添うログ基盤/pepabo_log_infrastructure_bigfoot - Speaker Deck)
2016年の Bigfoot の構成(出典: サービスに寄り添うログ基盤/pepabo_log_infrastructure_bigfoot - Speaker Deck)
しかし、社内で Bigfoot の利用が広がり、データ量の増加や計算リソースの需要の高まりによって、契約中の Treasure Data のプランに割り当てられたリソースでやりくりすることが2019年頃から難しくなっていました(色々な部署にインポート量の削減をお願いしたり、ワークフローエンジンに乗っているクエリをチューニングしたりしていました)。契約プランを変更することでより多くのリソースを利用することができますが、ペパボのユースケースでは利用料金が高額になることと、今後も需要が高まり続けることが想定されたため、利用料金の見通しが立てづらいことが懸念となっていました。また、マネージドな Digdag ではワークフローにスクリプト言語を利用できないことや、権限管理などの利便性など、幾つかの課題を解決できなかったため、BigQuery をデータウェアハウスとして利用する形での GCP への移行を決断しました。
GCP の選定理由
BigQuery の存在
2017年に社内向けのログ可視化ツールを開発した際にデータウェアハウスとして BigQuery を採用しており、当時の検証において、同様の処理を行うクエリの実行時間が Presto と比較して10分の1から100分の1になることが分かっていたため、この圧倒的な速度が最大の魅力でした。
BigQuery の場合、これまでと違って予めスキーマを決定する必要がありますが、2016年からの運用で行動ログに基本的に必要となるカラムが分かっていたため、大きな問題にはなりませんでした。また、計算が速く JSON_EXTRACT_SCALAR などの関数が強力なので、どうしてもスキーマを決定できない場合はスキーマレス的に JSON で格納しておいて、後からカラムごとにデータを整形することも可能です。
AI Platform の存在
ペパボ研究所や minne では、研究用途やサービスの機能提供のために既に GCP の AI Platform を利用していました。GCP を利用することで、例えば BigQuery ML との統合など、より便利に機械学習基盤を利用できるようになります。
コスト
GCP はプロダクトごとに課金体系が異なりますが、基本的に従量課金制なので「微妙にプランの割り当てを超えそうなので調整が必要」ということが起きません。また、データ活用基盤としての性能や利便性を向上させるための移設でしたが、料金自体も低額なため結果的にコストメリットによる後押しも生まれることになりました。
移設時の工夫
データウェアハウスの並行運用
本番環境や社内の業務運用でデータが活用されている基盤を一気に Treasure Data から GCP に切り替えることはできないので、以下の流れで並行運用を行いました。
- サービスのアプリケーションなどからのデータのインポートを一時的に二重化して Trasure Data と BigQuery に同じ行動ログや属性情報などの集計前のデータが存在する状態にする
- ワークフローを移行して Trasure Data と BigQuery に同じ集計後のデータが存在する状態にする(次項でもう少し詳しく書きます)
- アプリケーションからの参照先を BigQuery に切り替える
アプリケーションからデータウェアハウスへの参照は社内向けに提供している SDK やクライアントで抽象化されているため、バックエンドとして Tresaure Data と BigQuery を選択可能にしてサービスごとの実装の負担を少なくしました。
ワークフローの二段階移行
移設後のワークフローエンジンには GCP の Cloud Composer を利用するため、これまで「ワークフロー定義は Digdag + クエリは Hive/Presto」で実行していたワークフローを「ワークフロー定義は Cloud Composer + クエリは BigQuery Standard SQL」に書き換える必要があります。 ワークフロー定義とクエリを同時に変更するのが一番単純ですが、リスクが大きいため二段階での移行を行いました。
- Digdag + Hive/Presto のワークフローを動かしたまま、Digdag + BigQuery Standard SQL のワークフローを作成する
- Trasure Data と BigQuery で集計後のデータが同一である(= Standard SQL への書き換えが成功している)ことを確認する
- Cloud Composer + BigQuery Standard SQL のワークフローに切り替える
ワークフローが40〜50個ほど存在していたので、実際の移設に掛かった時間の殆どをワークフローの移行作業が占めています。
行動ログのスキーマ設計
予め決定が必要なスキーマ設計について、データを分析・活用する上で必要と考えられる基本的なスキーマの設計を基盤の担当者側で行うことで必要なカラムの欠落を防ぎ、サービスの担当者がサービスに固有なカラムの設計に集中することでデータの利便性を向上させました。
移設後の構成
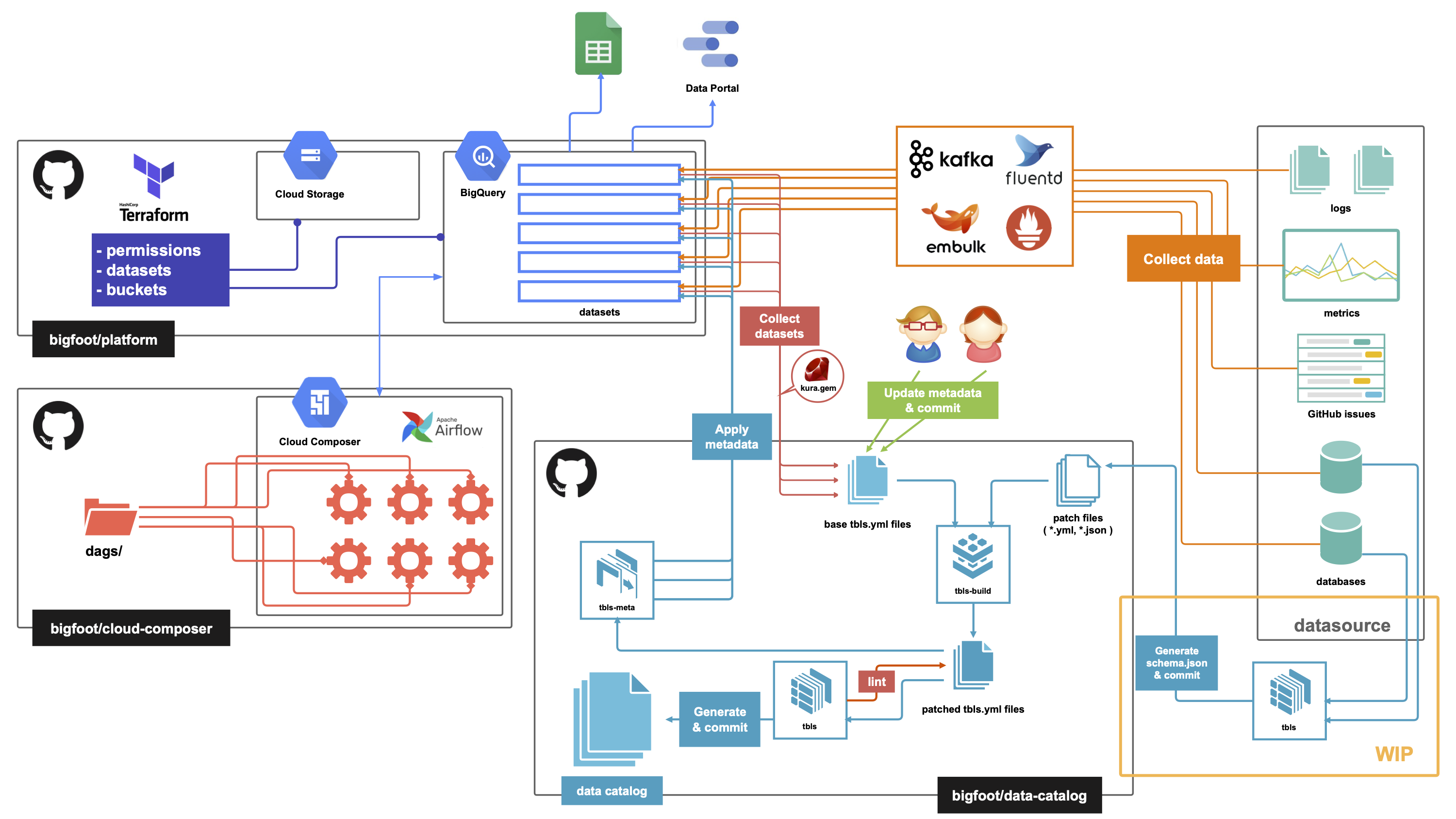 移設後の Bigfoot のフルアーキテクチャ図
移設後の Bigfoot のフルアーキテクチャ図
既に述べた通りデータウェアハウスに BigQuery を、ワークフローエンジンに Cloud Composer を利用する構成になっています。この記事では全ての構成要素には触れませんが、ペパボでは GitHub Enterprise を使った開発を行っており、リポジトリごとに以下のような要素を含む開発・運用を行っています。
bigfoot/platform
Terraform を使った Infrastructure as Code を行っています。また、社内用の Kubernetes クラスタの CronJob として ETL や Composer のテスト環境の作成/破壊を行っています。
- Terraform によるリソースの管理
- IAM
- BigQuery のデータセット
- Cloud Storage のバケット
- Cloud Composer の環境
- etc…
- 社内用の Kubernetes クラスタを使った CronJob の管理
bigfoot/cloud-composer
Composer 環境に載っているワークフローを管理しています。Drone と trinity によってテストやデプロイは自動化されており、非エンジニアの分析者でも SQL が書ければ GitHub Flow でワークフローを変更することができるようになっています。
bigfoot/data-catalog
BigQuery のデータセットやテーブル、カラムの description を管理しています。description を書くことで、分析者がデータの中身を理解することが容易になります。 tbls により BigQuery から抽出された description をコード化し、tbls-meta で変更が BigQuery 側に反映されています。Bigfoot にはサービスのデータベースに由来するデータも含まれるため、今後はサービスのデータベース側で既に整備されているドキュメントがある場合に自動的に BigQuery にも反映されるようになる予定です。
参考: データ基盤のメタデータを継続的に管理できる仕組みを作る(ペパボ編) / pepabohatena - Speaker Deck
bigfoot/starchart
starchart を使って、AI Platform を利用する機械学習モデルのコードとパラメータ、モデルのバージョンなどを管理しています。minne のシステムの一部として利用されている機械学習モデルも starchart によって管理されています。
参考: Google Cloud ML を用いた機械学習基盤の構築と運用/pepabo_ml_infrastructure_starchart - Speaker Deck
まとめ
ログ活用基盤「Bigfoot」の GCP への移設を行い、主にデータウェアハウスとワークフローに関連するリソースの拡充を行うことができました。顕著な例では、従来は実行に30分間掛かっていたクエリが1分程度に短縮されており、より効率的にデータを活用できる状態になったのではないかと思います。
また、データウェアハウスとワークフローの移設後も、@udzura さんによる Terraform の導入や、@k1low さんによるデータカタログの仕組みの整備が行われており、更に強い仕組みへと進化を続けています。
Bigfoot のような、データの収集・整備や、機械学習モデルの開発・運用を行うシステムは、機械学習工学として体系化されつつあるようです。ペパボ研究所でも、Bigfoot の開発・運用を通してこの分野の研究を進めていこうと考えています。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
