
ペパボ研究所の主席研究員の松本(@matsumotory)です。先日行われた、平成28年度第4回(IOT通算第36回)研究会で研究報告、および、運営委員として参加してきました。
研究会の現地で残念ながらインフルエンザにかかってしまい、登壇を急遽キャンセルすることになってしまいましたが、研究会予稿と発表スライドは作成済みですので本エントリで公開します。研究会予稿は以下のリンクから閲覧可能です。
簡単に今回の研究報告についてまとめておきますと、本研究の概要は、
Webホスティングサービスにて管理者がテナントごとのコンテンツを制御できないような高集積マルチテナントWebサーバ環境では,ホスト間のリソース競合を減らすことが安定運用にとって不可欠である.しかしホスト数が増えるにつれ,サーバ内の原因となるホストの監視や制御のコストも増加するため運用は難しくなる.本論文ではリソースの各指標の時系列データの変化点検出,ならびにサーバ内ホストやプログラムの各指標の重みづけによって,システムリソース逼迫状況下で多量のリソースを消費するリクエストを同定し隔離する自律的アーキテクチャを提案する.
という内容になっております。
また、研究を取り組むに至った背景としては以下の通りです。
Webサービスの低価格化とスマートフォンの普及に伴い,Webサービス利用者の数が増大している.そのような状況で,Webサービスを安定稼働させ,同時にWebサービス基盤の運用を効率化するために,Webサービスの基盤技術とシステム運用技術が注目されている.Webサーバの高集積マルチテナント方式は,単一のWebサーバに複数の利用者環境であるホストを高集積に収容することで,ハードウェアや運用のコストを低減するために利用される.しかし,高集積マルチテナント方式の一つであるWebホスティングサービスは,ホストに配置されるWebコンテンツの動作を管理者が詳細に把握できないため,ホスト間でのリソース競合をあらかじめ予測することは困難である.また,原因となるホストの調査についても,高集積にホストが収容されている場合,数多くのホストが原因対象となる事が多く,かつ,その対象が時間の経過と共に変化していくため,適切な調査と対策に要するコストが著しく高くなる.
続いて本エントリでは、研究会予稿の内容であるこれまでの課題や提案手法、実験と考察にまで踏み込んで紹介していきます。
これまでの課題と提案手法
研究会予稿の第一章の二段落で言及したように、従来の課題や我々が取り組んできた研究で解決できてない内容は以下のようにまとめられます。
従来のWebサーバの高集積マルチテナント方式におけるリソース制御は,ホスト名やファイル名,接続元IPアドレス等の同時接続数を計測し,設定された閾値を超えたらリクエストを拒否あるいは中断するような方式であった.その場合,同時接続数を超えると全く接続できなくなるため,利用者にとってはサービス停止と変わらず,サービス品質を低下させることになる.その問題を解決するために,我々は,リクエスト毎にCPU等のコンピュータリソースの使用量を限定可能な隔離環境で,リソースは制限しサーバの負荷を低減させながらも継続的にレスポンス生成処理を行うリソース制御手法を提案した.一方で,どのような状況においてどれぐらいのリソース使用量を割り当てるのが適切なのかということや,負荷原因の状況に応じて同時接続数制限との組み合わせをどう判定するかについて,刻々と変化しログの量も肥大化していく状況下で人力による調査に頼って判断することは依然高コストである.適切な制限項目や一定のルールに従った制限値を,いかにシステム管理者の運用コストをかけずに調査し制限するかという,ホスト単位で精細なリソース制御を行う際の課題が残っている.
そこで、第一章の三段落で提案したとおり、この課題を解決するための一つのアプローチとして以下のような手法を考えました。
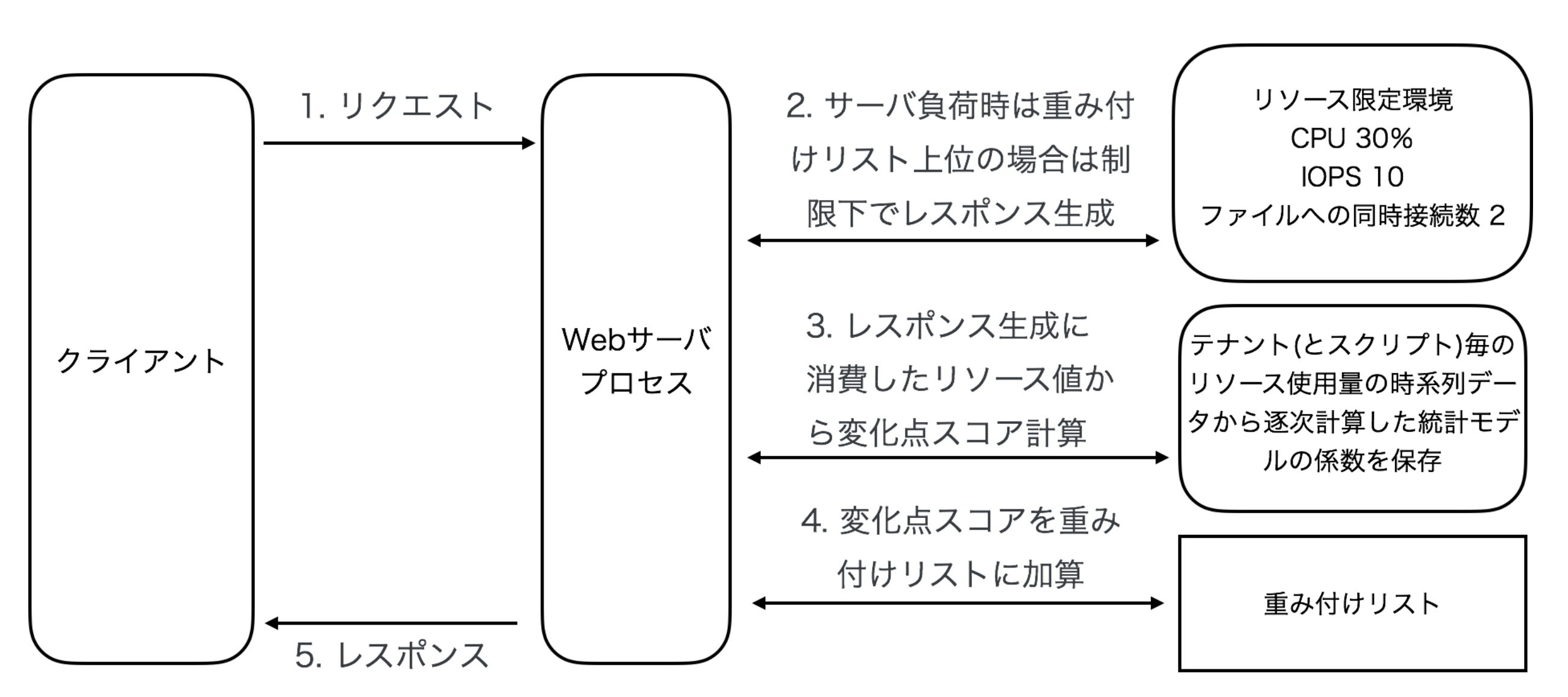
従来の手法による問題を解決するためには,時間とともに変化する各ホストのリソースの変化を都度把握し,原因となるホストを自動的に検出した上で,その変化の特性によって制限の組み合わせを決定し,自動で制限することが効果的である.本研究では,Webサーバのコンピュータリソースの特徴量を時系列データとして抽出してリクエスト毎に変化点検出を行い,原因となるホストやプログラムの変化らしさの重み付けを行った上で,サーバ全体のリソース逼迫時には,重み付けリストの結果に基いて自律的に原因となるリクエストを同定し分離するアーキテクチャを提案する.時系列データには,ホストおよびプログラム単位でのレスポンスタイムのデータとその時点の同時接続数を使用する.この時系列データに対して,変化点検出アルゴリズムChangeFinderにより変化点スコアを計算し,リクエスト時のホスト名とプログラム名にもとづいて,計測したスコアからリソースの傾向変化に寄与したホストおよびプログラムの重み付けリストを更新していく.そして,サーバ全体が高負荷状態になった場合に,重み付けリストに従って原因の可能性が高いリクエストのみを,リソース使用量が限定された隔離環境内で処理するようにする.これらを,Webサーバのレスポンス生成処理の過程に組み込むことにより,Webサーバはサーバ管理者の代わりに自律的に原因を解析し,必要な時にその原因に対処できる.
これらの課題と提案手法をまとめると、ポイントとしては、予稿の第二章「リソース制御の既存手法と課題」にも言及しているとおり、大規模で高集積なホスティングサービスのようなマルチテナント方式においては、
- 高集積マルチテナント環境下での過去のログを利用した負荷原因の調査コストが高く即時性が低い
- 負荷原因に対する制限設定や設定の組み合わせが人の判断に依存しており対応コストが高い
という課題にまとめることができます。
そこで、それらの課題を解決するためには、第三章「提案手法」で述べたとおり、
- 過去のリソース使用量の傾向と特徴を逐次学習しながら高速に負荷原因を自動検出する
- 検出結果に基づいて負荷の特徴にもとづいた即時性の高い自動制限を行う
というアプローチがあり得ること、それに加えて自身の運用経験上からも、
定常的にリソースを使用しているようなホストは,サーバのリソース使用量が他のホストと比較して多かったとしても,高負荷時の調査コストの観点から事前にリソース使用量が予測しやすく,経験的に突発的な高負荷の原因となることはまれであるため,それほど問題にならない.一方で,高集積マルチテナント方式における突発的な高負荷の原因とその調査コストの観点では,サーバのリソース使用量の変化が大きいホストやプログラムほど,問題になることが多いと考えられる.
のように仮説を立てられるのではないかと考え、そのアプローチと仮説検証のため、mod_mrubyやmruby-changefinderなどを実装して実験を行い結果の考察を行いました。
上記をフローに落とすと以下の図のようになります。
実験と考察
実験においては、まだまだプロトタイプ実装による予備実験レベルですが、研究報告としては興味深い話になると思い、予備実験とその考察までを含めた進捗を研究報告としてまとめました。
予備実験では、既存手法の比較のために、共著の山下(@pyama86)がこれまでに開発し、既に導入済みの負荷対応業務自動化ソフトウェアalbaの導入前後の負荷やアラート数などの遷移を考察したり、共著の田平(@tap1ra)によって今回の提案手法による重み付けリストを作成した場合に、albaでは検知が難しかった負荷対象の特徴を抽出できているかどうかなどを考察しました。実際の業務と並行しながら研究開発の業務もお手伝い頂き、お二人には感謝しかありません。
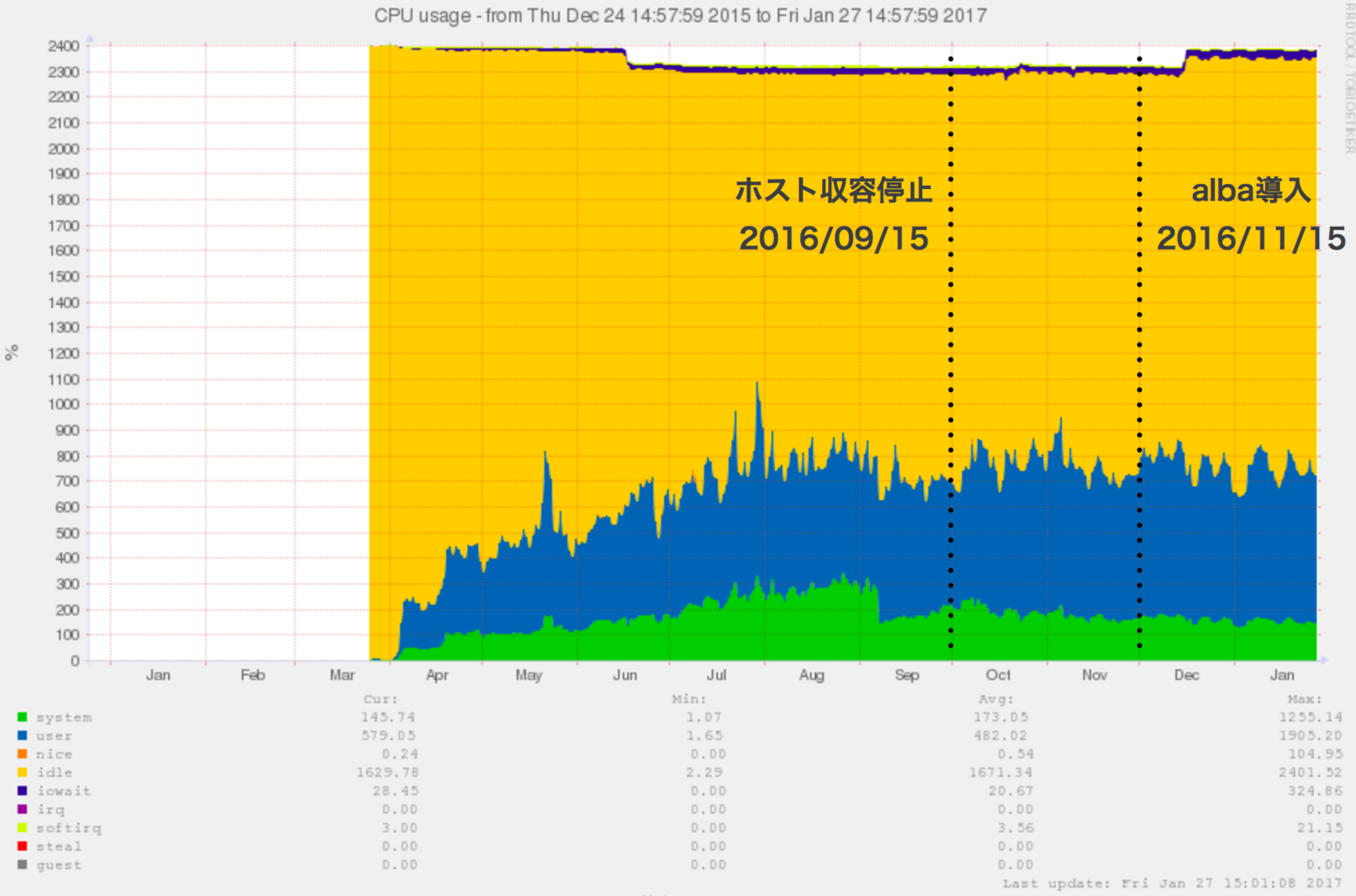
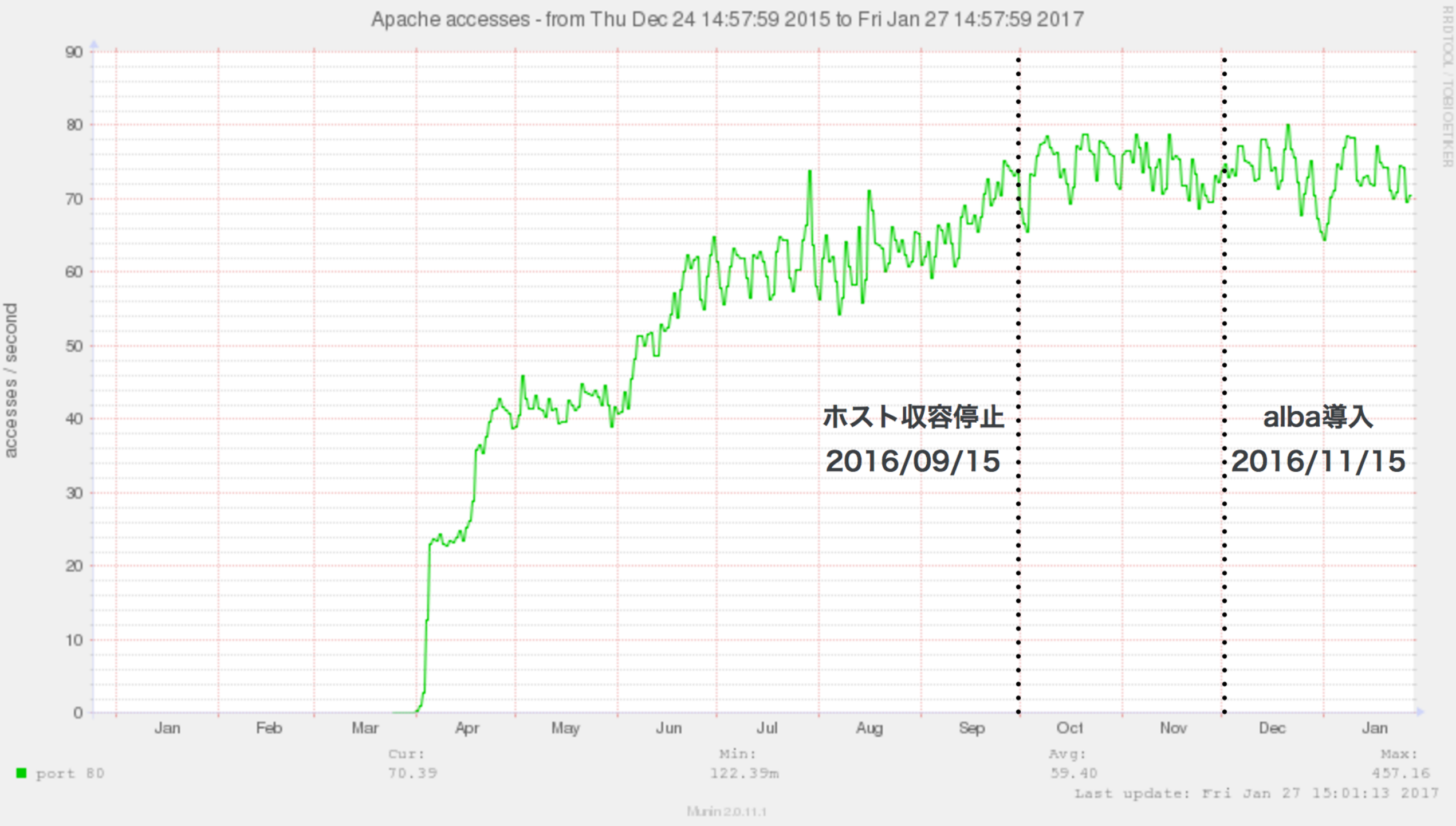
まずは、albaの導入前後でのCPUやアクセス数、アラート数の変化を以下のようにグラフ化しました。
- alba導入前後のCPU使用率の遷移
- alba導入前後の1秒間のアクセス数の遷移
- alba導入前後の一日のアラート数の遷移
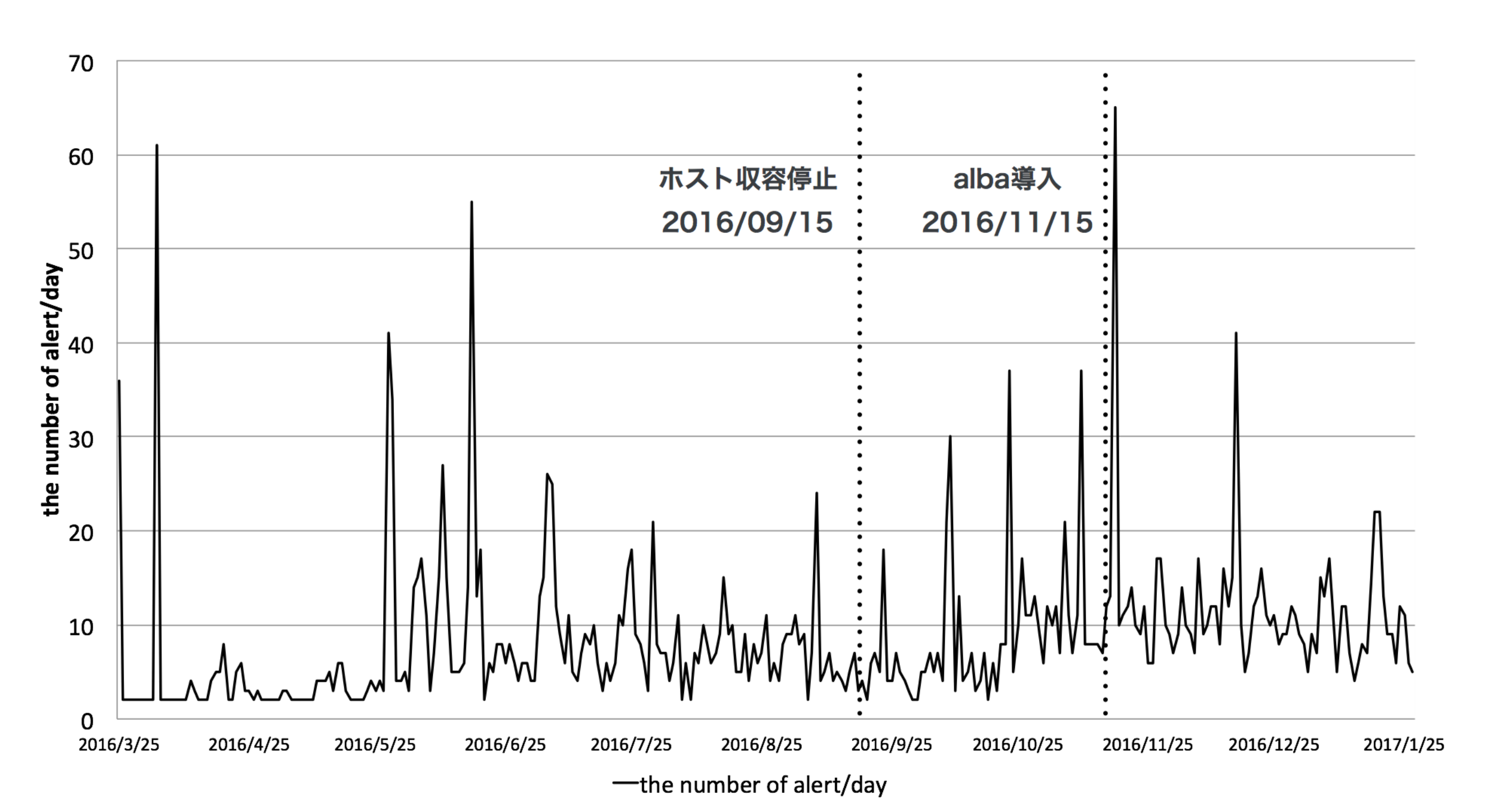
上記グラフからは、導入前後において優位な変化は見られませんでしたが、第四章「実験と考察」で言及したとおり、以下のように考察できます。
この理由としては,実運用上はアラート通知を受けてサーバを調査した際は既にalbaによって対応済みであり,設定反映のためのApacheのリロードによってアラート通知が行われる場合が多かったことが挙げられる.現在のalbaは,制限を行うためにApacheのリロードが必要であることから、リロードによって発生したアラートが検知されたものと推測できる.
この既存の運用手法を自動化したソフトウェアalbaに、今回の提案手法の重み付けリストの解析とその結果にもとづく適切な制限の組み合わせを実装すると、リロードも不要となる上に、変化らしさという指標にもとづいてより特徴を抽出できるようになるため、このあたりの課題も解決するのではないかと思っています。また、その根拠として、アラート後の対応可否についても指標に入れる必要があるでしょう。ただ、今回の研究報告では間に合わなかったため、次回の報告で結果を報告したいと思います。
また、重み付けリストにおける考察については、第四章に書いたとおり以下のように考察しました。
次に,albaと同一の作業フローによって,高負荷状態を検知した時刻の調査結果とその日のレスポンスタイムが記録されているログを調査した結果を,3.1節で示したような重み付けリストを生成するためのサンプル実装によって解析し,ホスト単位の変化点スコアから重み付けリストを作成した結果との比較を行った.
その結果,日々の高負荷対応のフローでは,直近数十分のアクセス数や転送量,レスポンスタイムから原因ホストを見つけ出すことができなかったが,1リクエスト単位のレスポンスタイムの平均値を比較したところ,問題となるホストの候補を検出でき,そのホストのみに着目すると高負荷時に大きく傾向が変化していることが分かり,負荷原因であることがわかった.一方,重み付けリストからは,該当ホストのアクセス数は少ないにもかかわらず,重み付けリスト上位に10位以内に位置し,問題となるホストとして検出できていた.この結果から,重み付けスコアにアクセス数の数を考慮した計算方法を考慮することでより精度が高くなると考えることができる.
まだ本番導入に向けての実験はいくつか必要になりますが、概ね既存の課題とそれを解決する方針が定まってきており、また、実験を行って定量的評価をしていく中で、日々の運用業務の中で新たな指標として計測しておく必要のある項目等も洗い出されて、研究のアプローチを実際のサービスに活かすためのサイクルもうまく回りだしているように感じます。これもまた、ペパボ研究所における研究開発と実践の取り組み方の良さがでているのではないかと思います。
今後の課題としては,提案手法の重み付けリスト機能や特徴を考慮した自動制限機能を定期実行のalbaをベースにmod_mrubyでリクエスト契機の処理に実装しなおした上で,プロダクション環境で動いているalbaと置き換えを行い,有効性がどの程度あるかを評価する必要がある.また,アラートが通知されたとしても,その後の対応がツールによって自動化されており対応が不必要であった場合や,アラートの受信から対応完了までの時間を評価の指標に加える必要がある.これらの評価を行うことで,サーバのリソースが逼迫していない状況でも,サーバのリソース変化に大きく寄与した原因となるホストやファイルの特徴を解析する必要性を示すことができる.
以上、簡単ではありますが、本研究の現在の状況を簡単にまとめてみました。
発表スライドは以下になります。
より詳細な提案手法の実装や実験結果・考察を含め、是非ご興味有る方は研究報告予稿(論文形式8ページ)も御覧ください。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
