
こんにちは、研究員の三宅です。インターネットでは @monochromegane として活動しています。ペパボ研究所では、機械学習を用いた新たなサービスの機能開発や運用手法についての研究開発を行っています。今日はペパ研の機械学習基盤の構想と、その運用を支援するために開発したツールについて紹介します。
はじめに
機械学習によってサービスの課題を解決していくためには、サービス資産との連携と、学習結果の利用が容易となる仕組みが必要となります。複数サービスを運用するペパボにこの仕組みを提供することを考えると、大規模にかつ即時適用可能な状態で運用するには基盤化が不可欠です。また、利用する学習結果は永続的なものではなくサービスの成長に合わせた継続的な改善が必要なため、機械学習基盤の運用においては改善結果の反映を継続、かつ安定して行うことができるかが課題となります。
このエントリではサービスと連携した機械学習基盤を検討し、運用における安定した改善結果の反映を実現するための作業工程の提案と、これらを補助するためのツールを紹介していきます。
機械学習基盤の検討
ペパ研では「システムの各要素が明示的な操作を経ずに特徴を認識し、その特徴や関係性に基づき、その時々の状況に応じた最適なサービスを提供する」なめらかなシステムというコンセプトの下、研究開発を行っています。そのため、ペパ研の機械学習基盤は機械学習を切り口になめらかなシステムを実現するための仕組みであり、前回のエントリにてその構成案を検討しました。
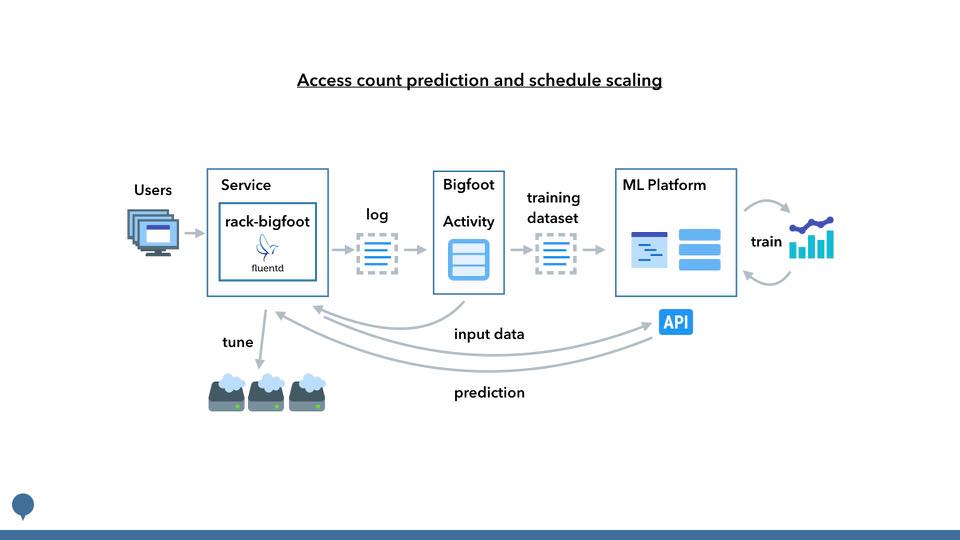
具体的には以下の要件を満たす必要があります。
1. ログやDBなどのサービス資産と連携できる
2. 比較的容易にモデルの構築と試行が行える
3. 学習結果を利用するための手段としてAPIを提供する
3.1 学習結果のローカル利用ができるとなおよい
4. 上記の仕組みがスケーラブルであること
独力での実装も考えましたが、いち早く有用なモデルを作り上げ、サービスに投入していきたく、今回はクラウドサービスを利用することとしました。上記要件を満たすサービスを検討した結果、今回はGoogle Cloud Machine Learning(以下 Cloud ML)を使っていくことにしました。
以下、機械学習基盤に求められる各要件とCloud MLでの実現方法について説明します。
1. ログやDBなどのサービス資産と連携できる
サービスの課題を解決するためにサービスの特徴を認識するための材料が必要です。例えば行動ログであればペパボのログ活用基盤であるBigfootと連携することができれば、機械学習基盤を個別のサービスと連携する作業が不要になります。 Cloud MLは入出力をGoogle Cloud Storage(以下、Cloud Storage)経由で行っており、BigfootがCloud Storageへの出力を担うことでサービス資産との連携を行います。
2. 比較的容易にモデルの構築と試行が行える
モデルの構築と試行とは、解決したい課題に対して機械学習の手法を選定し、投入するデータやチューニングを繰り返して最適な学習結果を得るための取り組みを言います。 この取り組みをできるだけ容易に行うため、機械学習のライブラリを利用した開発をすることを目標とします。実装済みの手法を利用することによる開発効率化、各種チューニングの初期値といったノウハウの活用が見込めるためです。 Cloud MLではOSSであるTensorFlowを利用することができ、上記のメリットを享受できます。
3. 学習結果を利用するための手段としてAPIを提供する
学習結果を利用するための手段としてAPIが提供されていることで、各サービスは個別に学習結果を取り込むことなくAPI経由で利用することができます。Cloud MLは学習時に入出力を定義して公開することで、APIとして利用できます(2017/01/16ではBeta機能として提供)。
また、3.1 学習結果のローカル利用ができるとなおよいとしていますが、学習結果の利用が大量かつ即時性が求められる用途、例えば物体検出や画風変換をリアルタイムに適用する場合、都度APIを叩いていたのでは処理が追いつかないため、学習結果をクライアント側に組み込むことで通信を不要とするといった要件に対応することを想定しています。これに関してはCloud MLの正式対応は将来になるとのことですが、学習結果をCloud Storageから個別に取り出すことで現時点でも対応できそうです。
4. 上記の仕組みがスケーラブルであること
深層学習を始めとする機械学習では精度を向上させるため、大量のデータセットを用いて、大量のパラメーターを学習していきます。学習には数時間から数日かかるようなものもあり、試行錯誤を効率よく繰り返すためにも、これらの期間を如何に短縮するかが課題となります。そのために計算機のリソースや台数が規模の拡大に対応できることが必要です。 また、学習結果をAPIとして利用する際も大量のリクエストを処理できるよう対応できる必要があります。 Cloud MLは、学習段階では分散型のトレーニングインフラ、利用段階では負荷分散サービスとの連携により、これらを実現します。
運用における安定した作業工程と支援ツール
機械学習基盤の運用において、利用する学習結果は永続的なものではなく、サービスの成長に合わせて継続的な改善を行いますが、新しく学習した内容が確認なく適用されてしまうことで意図しない結果が利用されることを防がなくてはなりません。そこで、学習結果のバージョン管理が必要となります。 学習ごとにバージョンを管理することで、既存の学習結果を利用してもらいつつ、新しい学習を進めることができ、必要なタイミングでサービスに利用してもらう学習結果のデフォルトバージョンを切り替えるといった運用が可能になります。 Cloud MLでは上記のバージョン管理機能を提供していますが、切替のタイミングは任意であり、正しく改善された状態での切替かを判断することができません。
そこで、Cloud MLを利用するにあたっては、バージョンを切り替える際に適切な訓練プログラム、パラメタ、入出力で学習されたものかを確認する工程を挟むことが必要になります。
StarChartは、これらのバージョン管理の切替における判断基準となる訓練プログラム、パラメタ、入出力まで含めてコード上で管理するために開発したツールです。本ツールを中心としたコード管理と、GitHubを通したバージョン切替時のレビューにより、予期せぬ学習結果がサービスに利用されることを防ぐことができます。
また、本ツールは学習時のジョブIDやCloud Storageのパス、バージョンに紐づくパラメタ情報の取得にまつわるCloud MLの細かな使い勝手も改善します。
StarChartによる学習、公開の流れは以下のようになります。
1. 訓練プログラムを管理する
以下のような構成で訓練プログラムをGitなどで管理します。ここでは訓練プログラムで学習する対象、学習結果として利用するものをモデルと呼びます。
.
├── MODEL_NAME
│ ├── setup.py
│ └── trainer
│ ├── __init__.py
│ └── task.py
└── MODEL_NAME
└── ...
2. 訓練プログラムを実行する
モデルを指定して訓練プログラムを実行します。ジョブIDやCloud Storageのパスなどはモデル名とタイムスタンプからStarChartが生成します。
sh
$ starchart train \
-m=MODEL_NAME \
-M=MODULE_NAME \
-- \
--your_train_param=FOO
3. モデルを公開する
学習が完了したらモデルを公開します。成功したジョブのうち、まだ公開されていないものが対象となります。バージョン名はジョブ名から生成します。また、公開時にモデルのパラメタ、入出力の情報をモデルファイルとして出力します。
$ starchart expose -m=MODEL_NAME
4. バージョンのデフォルトを変更する
新しく公開したバージョンが問題ないことが確認できたらモデルのデフォルトバージョンを変更します。モデルファイルのisDefault値を変更して適用できるので、このタイミングでパラメタやコードのレビューを行います。
$ starchart apply -m=MODEL_NAME
まとめ
ペパ研の機械学習基盤の構想と、その運用を支援するために開発したツールについて紹介しました。これから基盤を整備しながら有用なモデルをサービスに投入していけるよう研究開発を進めていきます。またStarChartもよければ使ってみてください。機能追加、不具合等あればPullRequestお待ちしております。
【PR】パートナー積極採用中!
ペパボ研究所では、新しいパートナーを求めています。詳細については、当研究所のトップページをご覧ください。
